


La publicación de la nueva guía de la MHRA, en marzo de 2018, nos permite recordar el objetivo principal de la Data Integrity: tener confianza en la calidad y la integridad de los datos generados, y poder rastrear las actividades. Este artículo ofrece una interpretación de los principales requerimientos, así como una aclaración sobre su aplicación.
El control de la Data Integrity se ha convertido en una preocupación principal de las autoridades de salud y, desde 2016, se han publicado hasta 6 guidelines1 sobre el tema, editadas por diferentes instancias reglamentarias. Estas directrices, algunas aún en estado de borrador, revelan cierta convergencia a nivel de expectativas. La detección en el pasado de numerosos incumplimientos de las buenas prácticas de fabricación en el control de datos, así como de fraudes tipificados, ha llevado a los inspectores a aclarar su posición sobre el tema, y a formarse al respecto. El número de Warning Letters, de Non Compliance Reports y demás requerimientos ha aumentado considerablemente en los últimos años.
Data Integrity
La integridad de datos se define habitualmente como una medida según la cual los datos críticos se mantienen completos, coherentes y exactos (complete, consistent and accurate) a lo largo de su ciclo de vida. Si bien el concepto no es reciente –la IEEE utilizaba la misma formulación para definirlo ya en los años 1990, y hay Warning Letters emitidas por la FDA en los mismos términos a comienzos de los años 2000–, su control pasa por nuevas disposiciones debido a la creciente digitalización de los procesos, a la globalización de las actividades y a la multiplicación de los sistemas informáticos por los que transitan los datos.
Reliable Decision-Making
Para que una decisión sea sólida, la integridad de los datos en los que se basa debe estar garantizada. ¿Qué fiabilidad podemos otorgar a una decisión farmacéutica tomada a partir de datos erróneos?
Es fundamental que el sistema de calidad de una organización permita la identificación y el control de los puntos vulnerables de los datos críticos, tanto si son electrónicos o como si se han registrado en papel.
ALCOA
Las autoridades coinciden en considerar que la Data Integrity se cumple cuando se reúnen los requisitos ALCOA (Attributable, Legible, Contemporaneous, Original y Accurate). Este acrónimo recoge las características necesarias para demostrar que se ha llevado a cabo una correcta documentación de todos los eventos que han afectado a los datos y que dichos datos puedan utilizarse como base para tomar una decisión. En algunas publicaciones también es posible encontrar las siglas ALCOA+, algo más precisas al añadir los términos Complete, Consistent, Enduring (duradero) y Available (disponible).
La Data Integrity es así un requisito fundamental del sistema de calidad farmacéutica, y la principal expectativa es que los principios ALCOA se apliquen a todas las actividades regidas por los GxP (ver cuadro 1).
Los fabricantes, distribuidores y operadores deben ser capaces de detectar cualquier deficiencia en la organización o en los sistemas que pueda conllevar una alteración de los datos, y provocar una decisión errónea. Esta detección atañe tanto a las alteraciones de datos voluntarias como involuntarias, y a los medios electrónicos y de papel.
Las distintas directrices emitidas en materia de Data Integrity han introducido una terminología que es importante asimilar, aunque algunas definiciones pueden variar ligeramente de un texto a otro. La correcta interpretación de algunos de estos términos favorece un mejor control de la integridad de datos.

Metadatos
Por metadatos se entiende la información vinculada a un determinado dato, que proporciona contexto y facilita su comprensión. La integridad de los metadatos debe estar garantizada. Por ejemplo, el vínculo entre un dato y su marca temporal (la fecha y hora de adquisición) debe siempre conservarse, y esta marca temporal debe también cumplir los requisitos Alcoa.
Registros estáticos y dinámicos
Las instancias reglamentarias, y especialmente la FDA, distinguen los registros estáticos de los registros dinámicos. En un registro estático, los datos son fijos y no hay necesidad de modificarlos. Es el caso, por ejemplo, de un registro en papel o de una imagen electrónica. Un ticket de pesaje, por ejemplo, no necesita un tratamiento posterior para poder ser utilizado y contiene en principio toda la información necesaria para interpretar el resultado.
No ocurre así con el formato de registro dinámico que, en este caso, autoriza una interacción con un usuario para su explotación. En un cromatograma, por ejemplo, pueden modificarse los parámetros de integración, apareciendo un pico de integración más o menos amplio. El carácter dinámico de este tipo de registro debe conservarse para poder obtener el mismo resultado a partir de los mismos datos. En el caso del cromatograma, esto significa que quizás no baste con una impresión después de la integración para interpretar el resultado, y que es necesario mantener el acceso a la información electrónicamente almacenada.
Audit trail
El audit trail es un registro de eventos diario y seguro que rastrea con marcas temporales las modificaciones realizadas en el sistema. Este registro es generado por el propio sistema. El objetivo del audit trail es poder reconstruir los eventos relacionados con cualquier creación, modificación o eliminación de datos críticos.
El audit trail se considera un metadato porque permite conocer el “cuándo”, el “quién”, el “qué” y el “por qué” de una modificación.
Copia de seguridad y archivo
La copia de seguridad es una copia de los datos, metadatos y parámetros de configuración que se conserva de cara a una restauración en caso de pérdida de los datos originales.
El archivo es el almacenamiento de datos a largo plazo, con vistas a poder consultar los datos durante todo su periodo de conservación.
Debe mantenerse la integridad de todos los datos, tanto copiados como archivados.
Data Lifecycle
El Data Lifecycle (ciclo de vida de los datos) es el conjunto de fases del proceso por el cual los datos se registran, procesan, revisan, reportan, conservan, recuperan y se someten a revisión. Este ciclo se extiende desde la generación o adquisición de un dato o conjunto de datos hasta su destrucción o borrado.
La integridad de datos debe garantizarse durante todo su ciclo de vida. Esto implica controlar el Data Lifecycle. En otras palabras, deben identificarse y entenderse todas las etapas de cada dato o registro crítico (ej.: creación, almacenamiento, transferencia, modificación, archivo) para poder detectar cualquier riesgo de modificación o alteración. La revisión del Data Lifecycle ha de permitir entender todas las manipulaciones realizadas en los datos (ej.: cálculos, exclusiones) permitiendo llegar hasta los datos brutos. Esta revisión forma parte del sistema de Data Governance.
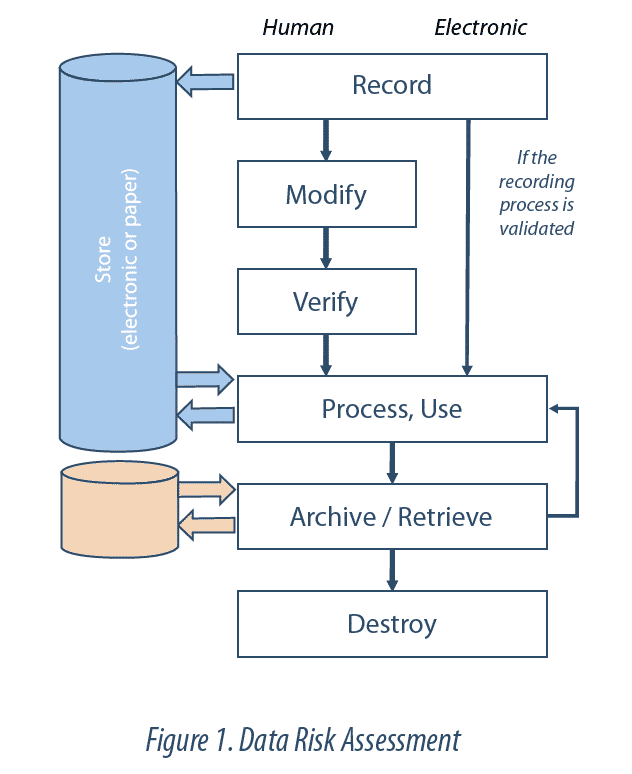
Data Governance
El Data Governance es el conjunto de disposiciones destinadas a garantizar que los datos, independientemente del formato de generación, se registran, procesan, almacenan y utilizan de tal manera que se garantiza un registro completo, coherente y exacto a lo largo de su ciclo de vida.
El Data Governance forma parte del sistema de calidad farmacéutica y se basa en 3 pilares, que son el comportamiento, la organización y la técnica.
Una conducta con arreglo a los principios de Data Integrity implica, en particular:
- que el personal sea consciente de la importancia de la cuestión (mediante, por ejemplo un código de conducta, o un código deontológico),
- la implicación de la dirección,
- la transmisión y el tratamiento correcto de las desviaciones.
Las disposiciones organizativas pueden incluir, por ejemplo:
- un enfoque basado en el riesgo,
- la adopción de procedimientos,
- la formación del personal,
- la segregación de roles,
- la revisión de datos y la realización de controles rutinarios,
- la revisión periódica y la vigilancia del sistema.
Los dispositivos técnicos incluirán, entre otros, los siguientes aspectos:
- la utilización de sistemas informáticos o automatizados validados;
- la implementación de Audit Trails;
- la seguridad de los soportes de registro;
- el control de los accesos;
- la implementación de sistemas de copia de seguridad y archivo;
La revisión del sistema de Data Governance permite evaluar, en cada departamento, la correcta interacción entre los comportamientos, las medidas organizativas y los dispositivos técnicos.
Dado que la Data Integrity se ha relacionado durante mucho tiempo con un problema de informática, se han implementado con frecuencia dispositivos técnicos, ya sean funciones informáticas de seguridad y control, o de automatización de procesos, con el fin de limitar los errores derivados de las intervenciones humanas.
La implementación de soluciones técnicas, no obstante, no basta por sí sola si no va acompañada de un uso adecuado y eficiente. El audit trail, por ejemplo, debe revisarse para garantizar que no se ha producido ninguna modificación no controlada. Esta revisión no se efectúa de manera exhaustiva en todos los eventos que se han registrado en el sistema, sino que se focaliza en las diferencias observadas en el funcionamiento del proceso de obtención de los datos, únicamente en el caso de los datos críticos. La existencia de un audit trail en un sistema no garantiza por sí sola la ausencia de modificaciones no controladas: es necesario que las reglas de explotación del sistema estén definidas y sean seguidas, a través por ejemplo de un procedimiento de revisión sistemática de determinados eventos, o la utilización validada de un informe de revisión en caso de excepción.
El aspecto organizativo de la Data Integrity requiere una cierta madurez en la materia, así como una buena implicación por parte de los departamentos y la dirección, y una toma de conciencia de los riesgos a nivel de la empresa, lo que a veces necesita de una evolución de la cultura empresarial.
La Data Governance utiliza un enfoque basado en el riesgo para identificar los datos críticos (Data Criticality) y sus posibles riesgos de alteración (Data Risk), a fin de ajustar los esfuerzos de control a las necesidades, y de manera equilibrada con las demás actividades de calidad. El nivel de esfuerzo a realizar para controlar los datos se determina en función de su criticidad y de su impacto en los CQA (Critical Quality Attributes) o los datos de liberación. De igual modo, el esfuerzo debe modularse en función de la posibilidad de detectar un alteración de datos. La eficacia de las disposiciones implementadas debe, por último, controlarse y revisarse periódicamente.
Data Criticality
Para determinar la criticidad de un dato, hay que hacerse las siguientes preguntas:
- “¿En qué decisión influye el dato? “
- “¿Qué impacto tienen los datos en la calidad o la seguridad del producto? “
La importancia de las decisiones en las que influyen los datos y el impacto de estos en las mismas son variables. El esfuerzo debe concentrarse en los datos más críticos.
Data Risk
El nivel de vulnerabilidad de un dato, frente a una modificación no controlada (voluntaria o no), se evalúa mediante un análisis de riesgos. Entre los factores a tener en cuenta en este análisis se incluyen la complejidad del proceso analizado, su nivel de automatización o la subjetividad de la interpretación de los resultados. La evaluación abarcará todo el perímetro del proceso, y no solo las funcionalidades o tecnologías informáticas, de manera que se tengan en cuenta la interacción con los usuarios o las interconexiones entre sistemas, en cada etapa del ciclo de vida.
La validación de los sistemas informáticos, aunque sigue siendo necesaria, actualmente no es suficiente para garantizar el control de los riesgos relacionados con la integridad de datos.
Aquí es donde reside la principal evolución del enfoque a considerar: la implementación de un Data Management (véase Gráfico 2).
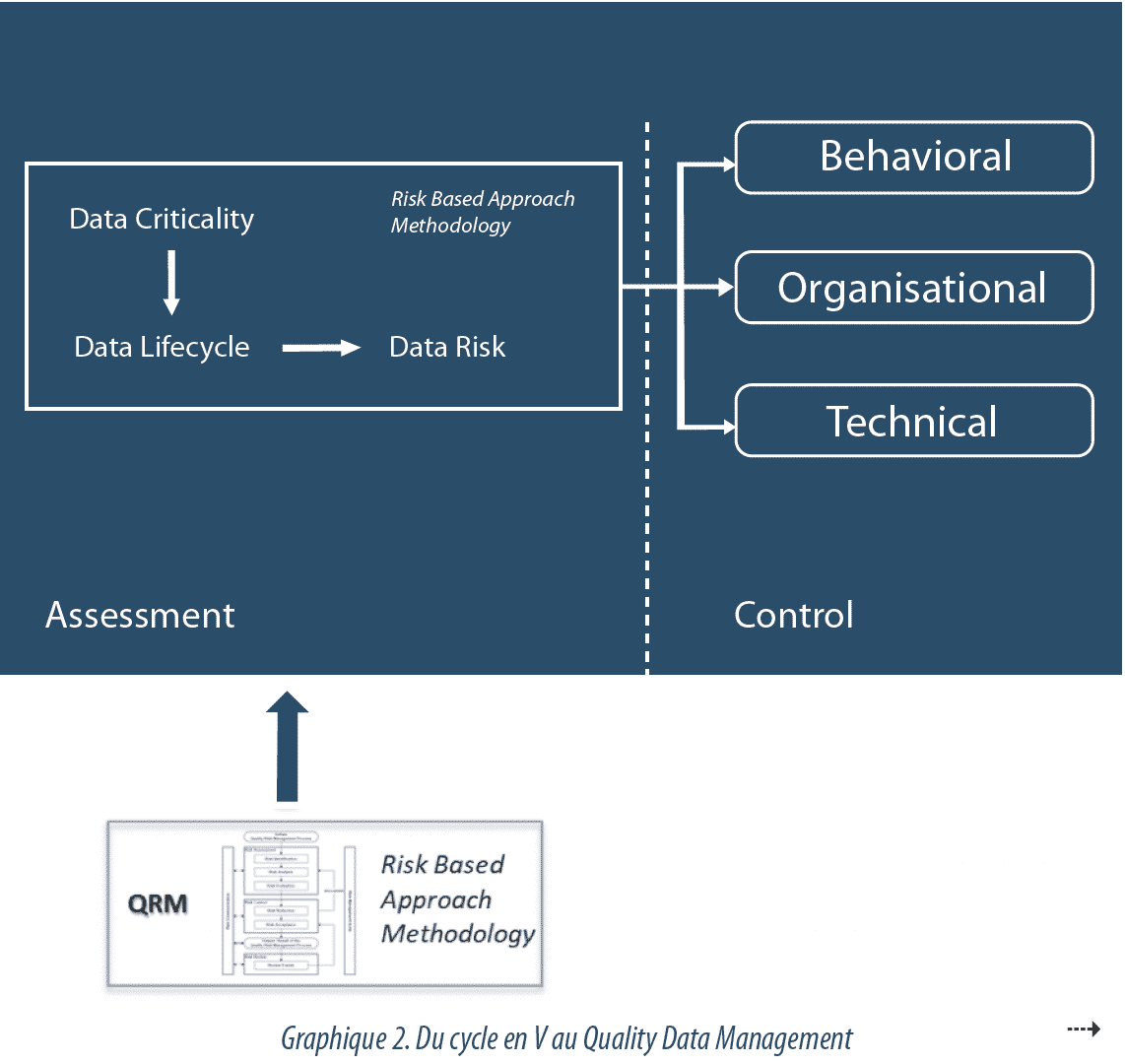
Data Management
Inicialmente, el control de la Data Integrity se basaba en la validación de los sistemas informáticos. Cada sistema seguía un ciclo en V, en el que se definían, desarrollaban y ponían a prueba las diferentes funciones. El informe de validación determinaba la conformidad del sistema. Posteriormente el enfoque evolucionó hacia un control de riesgos que tenía en cuenta el entorno del sistema y su ciclo de vida. Este Risk-Based Approach, recogido en particular por la GAMP52, tenía en cuenta la verificación de la implementación de diversos aspectos organizativos para la explotación (formaciones, procedimientos, etc.), pero se circunscribía al sistema.
En la actualidad, este enfoque ha quedado obsoleto ante la multiplicación de los sistemas informáticos, a menudo interconectados entre sí, y su alto nivel de configuración, a lo que hay que sumar unos flujos de gran complejidad. Es necesario pasar de un modelo centrado en los sistemas a un modelo centrado en los datos, con la adopción de un Quality Data Management, estructurado y regido por el riesgo, que garantice un tratamiento coherente dentro de una misma organización. Este modelo conlleva una sensibilización continua sobre la integridad de datos en todos los procesos críticos, teniendo en cuenta los datos electrónicos, los datos en formato papel y las interconexiones entre ambos a lo largo del ciclo de vida, y no solo en los sistemas críticos.
El Data Management está dirigido por un responsable, el Quality Data Manager, dependiente del departamento de Calidad, y en coordinación con todos los servicios que gestionan o manipulan los datos críticos que respaldan las decisiones farmacéuticas. Este responsable, además de garantizar los principios y normas de Data Integrity, dirige la implementación, presta soporte al personal operativo y mantiene informada a la dirección sobre los riesgos más altos.
Conclusión
Las buenas prácticas de Data Management y Data Integrity generan confianza respecto a la solidez de las decisiones farmacéuticas y forman parte del sistema de calidad. Los riesgos de alteración de datos deben controlarse igual que los riesgos relacionados con los productos, ya que la calidad de un producto farmacéutico está estrechamente relacionada con la calidad de sus registros de trazabilidad.
Partager l’article


