


Summary
- 6 Sigma and Operational Excellence. Just Common Sense?
- How many values are necessary to have a representative sample?
- Statistical modeling: The need for a reliable approach to improve process knowledge and understanding
- Bayesian approach in cosmetical research : Application to a meta-analysis on the anti-pigmenting effect of vitamin C
- Comparability, equivalence, similarity… How statistics can help us to demonstrate these. And soon, the end of blind testing for health authorities and manufacturers.
- Maintenance of the validated state, a stage in the validation cycle.
Many manufacturers wonder about this question of sample size… Formulated implicitly in the past, this requirement now appears quite explicitly in many normative references.

For example, the standard ISO 13485(1) during verification and validation of the design and development of medical devices, requires: “The organization must document the validation plans which comprise methods, acceptance criteria, and when appropriate, the statistical techniques accompanied by a justification of sample size”.
Yet there is no existing, single, recognized, undisputable formula that can be applied to all studies to calculate sample sizes. Indeed the number depends on many factors, associated with the objective and the performance of each study. Manufacturers then sometimes feel helpless when faced with this requirement which necessitates solid statistical knowledge, and especially, rigor in its application.
Moreover, the representativeness of a sample is not solely linked to its size. It depends directly on the way in which the experimental plan is constructed, which must avoid introducing selection bias.
So the manufacturer is obliged to answer a set of questions underlying each problem in order to propose a relevant and appropriate experimental plan which will answer their problem, in line with their constraints.
This article deals firstly with the setting up of the experimental plan, then tackles the idea of sample size for quantitative and qualitative variables. Focus is given to certain themes, for example the standard ISO 2859-1.
1. The experimental plan as a basis for discussion
The choice of experimental plan is the fundamental element with which to begin; in fact, it is essential to construct a matrix of experiments which will meet the objective. For this, different questions are raised; the French QQOQCCP method (What, Who, Where, When, How, How many, Why) can be applied to guide reflection.
1.1 Why is this study being conducted?
This is the central question be asked: what is the objective of the study? why are we planning to launch this study, what are we trying to show? The precise, correct formulation of the objective guides us in the direction of the appropriate statistical approach. Different families of statistical methods may be used, such as for example:
- Descriptive methods, which allow measurement of the performance of a process or an equipment item, or analysis of a results history…
- Exploratory methods, which allow the study of interactions between process parameters, or investigation of the impact of process parameters on a results history…
- Decisional methods, which allow assessment of the impact (or lack of impact) of a change, measurement of the influence of factors and their interactions on a response…
Formulating the objective correctly will also allow a quantified objective to be defined. For example, when we want to estimate a mean, we need to have an idea of the expected precision level. Or when an improvement is expected, the order of magnitude of the difference we are trying to detect needs to be quantified.
1.2 With whom and when?
These questions concern planning and are important for the study to proceed in a calm manner.
The schedule and the human factor sometimes represent significant constraints when developing the experimental plan. These constraints may be direct (limited number of operators, of machines…) or indirect (economic choice to carry out tests over a limited time period). For example, if the laboratory technician can test a maximum of 10 samples per series, it is necessary to provide for an experimental plan that takes into account a series factor that will be called a “blocking” factor.
In addition, spreading tests out over time can have the consequence of creating a “noise” factor which will make the experiment less effective. It is then possible that the study will be biased and become inconclusive. For example: we wish to compare 2 HPLC systems. For this, we test one sample x times on the first HPLC system. The following week, we test the same sample x times on the other HPLC system. If a discrepancy is noted, is it due to the difference between the 2 systems or instability of the sample over time? This experimental plan is therefore not appropriate: both factors vary simultaneously and are therefore called “confounding”.
When several time or resource constraints are superimposed, an analysis of potential confounding factors must be performed beforehand, in order to remove or limit bias in the analysis.
1.3 What and where?
Two questions lie behind this “what”.
- Which samples (what?) and at what stages (where?)
On which product(s) will the study be conducted? On which lot(s)? At which stage(s) of manufacture? … A process of reflection and discussion should be undertaken in order to define the approach strategy and to evaluate it in terms of risks: quality risk, customer risk, industrial risk… In fact it is always preferable from a financial point of view to reduce the number of experiments by rationalizing the choice of samples tested, but the question of the appropriateness of a “worst case” approach should also be asked. Is it defensible from the point of view of quality? Might the customer disapprove of it? Will not the company miss valuable information? This reflection and discussion process should be shared between product and quality experts.
- Which measurement method?
It is generally possible to measure many things in samples! The idea is therefore to choose the measurement method that is most appropriate to meet the study objective. If we want to validate the homogeneity of a product, which analytical method(s) should be chosen to describe this parameter? In some cases it is possible to select several measurement tools or methods, but some choices may prove more appropriate than others (e.g. dispersion of an organic component in an aqueous solution).
1.4 How?
The “how“ approach is different depending on whether the study is analytic or enumerative.
A study is called analytic when there is not an identified, finite population: the analysis is carried out on a sample generally constructed for the study.
For example, we wish to verify the homogeneity of a bulk solution in a tank. How should the samples be selected to be representative of all of the tank? This question is also essential here and the manufacturer will answer it, amongst other questions, according to the type of tank and the resources they have to sample their solution.
A study is called enumerative when it is conducted on an identified, finite population, from which a sample is selected.
For example, we wish to inspect manufactured units in order to ensure there are no defects. How should the sample best be selected to be representative of the lot as a whole? This question is essential to guarantee the representativeness of the sample and the manufacturer will answer it in accordance with lot size, as well as in accordance with the way in which their lot was manufactured and their possible sampling strategies.
The manufacturer may then decide to use a reasoned, rational approach to be representative, or trust in chance: randomness is a very good method for obtaining good representation and there are random number tables that make working under controlled randomized conditions possible.
The difficulty with chance is that it is difficult to apply when the human factor comes into play. Many studies(2) have demonstrated that the human brain is not capable of generating random numbers correctly. Even with the best of intentions, their choice will be altered by perception bias which will influence their decision: bias linked to their interpretation of the situation, their a priori assumptions, their previous choices, their reasoning, their culture… This is why the use of a tool which generates a true random selection should always be favored as far as possible.
1.5 Structure of the experimental plan and how many?
Once these different questions have been addressed, the structure of the experimental plan can be developed, meeting the objective and taking account of constraints.
From this experimental plan and the study objective, the statistician will deduce which statistical method is most appropriate for the problem.
They will then be able(finally !) to address the idea of number and answer the initial question: “How many?”
Subsequently, a proposal will be made on the basis of an absence of bias in the experimental plan.
2. Quantitative tests
Many standards require tailored sample sizes and ask manufacturers to justify their choice. It is in fact important to calculate a sample size properly before conducting a study in order to have a high chance of demonstrating the desired result, in a statistically significant manner. In statistics, this is called “power”. An inappropriate sample size (generally too small) may have consequences for the significance of statistical results, and therefore for the conclusions of the study.
The quality of the study therefore depends directly on the number of samples tested (or the number of tests to be carried out). Other parameters also intervene: the probability of error and the value or difference expected for the criterion measured. This is why it is not necessary to systematically use large samples. In some areas, a large sample size can also make the study less feasible.
2.1 Sampling fluctuation
Beyond the obvious regulatory constraints, the choice of an appropriate sample size determines the quality of the study: the more measurements there are, the more precise study will be. But what level of precision is really needed? The analysis of a sample gives a “one-time” estimate of the parameters of the population from which it was derived; this estimate will change when another sample is analyzed, but will always fluctuate around the same central trend. This is called “sampling fluctuation”. For example, the concentration of a solution can be measured five times: 50.3 – 51.2 – 50.4 – 49.1 – 48.8 ng/ml, which gives a mean of 49.96 ng/ml. If five measurements are again made, these will be different, for example: 50.5 – 49.3 – 50.3 – 51.4 – 52.2 ng/mL, which gives a mean of 50.74. The distribution of the means will be less dispersed than the distribution of individual values, and therefore closer to the “true” value (although the latter is rarely known).
The graph below illustrates the precision of a mean of 5 values (red curve) selected randomly from a distribution of individual values (blue curve = simulation of a normal distribution with a mean of 50 and a standard deviation of 1). So, the mean of 5 values will generally be between 49 and 51. Is this level of precision satisfactory given the study objective?
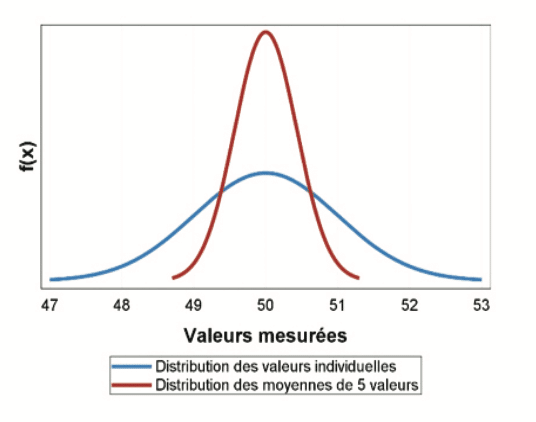
Generally confidence intervals are used to obtain a priori knowledge of the precision of the final result. For example, we want to estimate the number of measurements to be made to calculate a mean; the variability of results has been measured beforehand and the standard deviation is 0.88. The formula for the confidence interval for the mean can be used to estimate precision in accordance with the number of measurements:

Where:
m0 : sample mean
t : Student’s law fractile
α : probability of error
n : sample size
s : standard deviation of the sample
So if 5 tests are performed, the mean will fluctuate around its value of:
± t(1-α/2 ; n-1) × s/√n = ± 2,776 × 0,88/√5 = 1,09 units, in 95% of cases (alpha=5%)
If 10 tests are performed, the mean will fluctuate around its value of:
± t(1-α/2 ; n-1) × s/√n = ± 2,262 × 0,88/√10 = 0,63 units, in 95% of cases (alpha=5%)
If 20 tests are performed, the mean will fluctuate around its value of:
± t(1-α/2 ; n-1) × s/√n = ± 2,093 × 0,88/√20 = 0,41 units, in 95% of cases (alpha=5%)
The greater the number of tests, the better the precision level and therefore the confidence interval narrows; however, the gain in precision is not correlated linearly with the number of measurements.
Therefore, the study objective should clearly formulate expectations in terms of the precision of the desired result.
2.2 The risks of making an error (called “probability of error”)
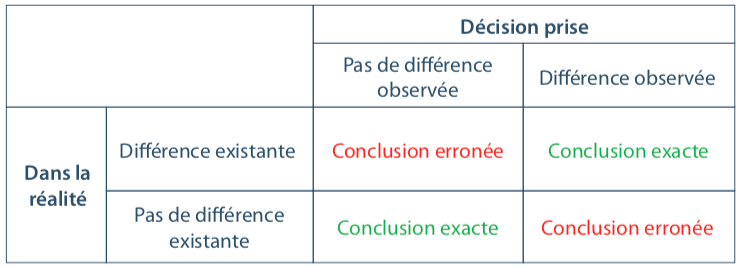
It is essential to keep in mind that working with a sample systematically causes two risks of making an error, and two chances of taking the right decision.
The following table visualizes the 4 possible conclusions:
These risks of making an error form an integral part of any sample-based study; we will always seek to limit them.
2.3 Illustration of the power of a comparative test
it is necessary to calculate sample sizes a priori in order to obtain sufficient statistical power. Power is the capacity of a test or a model to demonstrate the desired difference, if it exists, between several populations.
For example, if the power of a chosen experimental plan is 50 % for a desired difference of 1 μg/ml this means that analysis of this plan will allow a significant difference between groups to be concluded only one in two times, if this difference is really 1 μg/ml.
So, there is one chance in two that the plan will not demonstrate the difference of 1 μg/ml, which causes a waste of time and money, and doubts regarding the efficiency of the study objective.
In the context of a comparative test of 2 populations, a small sample will be able to demonstrate a rather marked differences between the two groups:
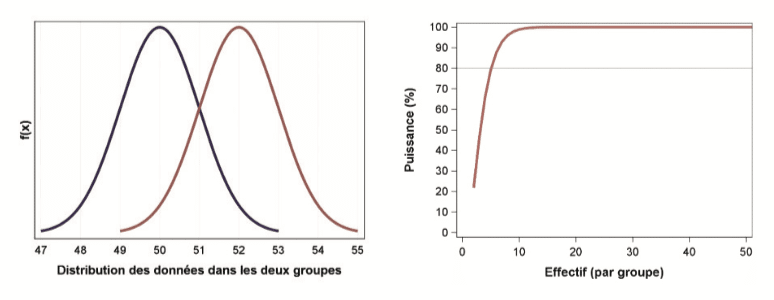
Conversely, to demonstrate very fine differences between the two groups, a large sample is necessary. As the following graph shows, by carrying out 50 tests in each group, a difference of 0.5 units will only be detected in 70% of cases:
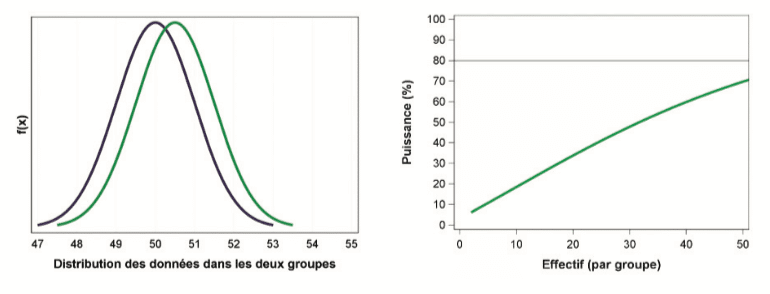
A process of reflection and discussion is now necessary: even while dispensing with all bias linked to the sampling procedure and study reproducibility, what difference is appropriate from a scientific point of view? Is it really appropriate to study such a weak effect?
2.4 Equivalence tests
Statistical tests have the use of meeting a precise objective. They should be used wisely, in their context of application. Comparative tests, currently very common in statistical software, can be used when the study objective is to demonstrate differences in distribution of a measurement between several populations.
For example, when comparing the mean of two groups, and when the test is significant (for example, p-value = 0,01 < 0,05), this means that the difference observed between the two means in the study has a 1 % chance of being observed “by chance”, if the two groups were derived from the same initial population. As the probability is low, we conclude that it is preferable to reject the hypothesis of equality of means (H0). When the p-value is high, the test is inconclusive, as it does not demonstrate a difference between the two groups. But this does not mean for all that, that there is no difference! It means that the measurements made on this sample did not allow a difference to be detected (given sampling fluctuation, another experiment could perhaps allow one to be detected).
In industrial statistics, it is common to have to show the absence of impact of a change. In this case, equivalence tests should be favored. These are based on the comparison of a confidence interval with fixed equivalence bounds.
For example when comparing 2 means, if the confidence interval of the difference is contained within the equivalence bounds, a conclusion of equivalence is possible:
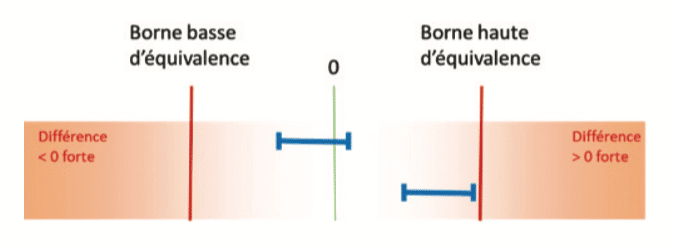
On the other hand, if the confidence interval for the difference cuts across one of the equivalence bounds, the sample will not allow a conclusion of equivalence:
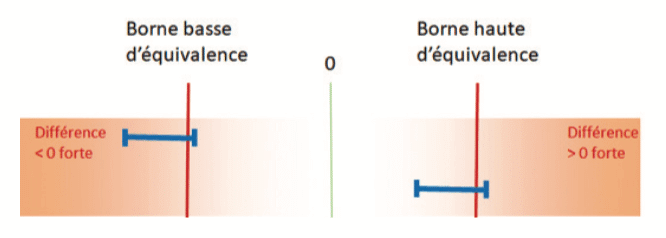
But this does not mean for all that, that there is a difference! It means that the measurements made on this sample did not allow equivalence to be demonstrated (given sampling fluctuation, another experiment could perhaps have demonstrated this).
The difficulty of equivalence tests lies in the choice of appropriate equivalence bounds. They are fundamental as they impact the result of the statistical test directly. They should be fixed in light of the knowledge that the manufacturer has about their methods, their processes, and their industrial, customer and quality risk. As with a comparative test, calculation of the power of the equivalence test is highly recommended.
2.5 Other tools
When the objective is exploratory in nature, the question of the appropriateness of the systematic use of statistical tests should be asked. “Statistical proof” is not necessarily provided by a p-value; the expert can rely on descriptive tools such as Boxplots, or measure the strength of the effect via effect size measurements(3). So by combining statistical tools with their professional expertise and their perspective on the situation, they will be able to draw solid conclusions based on their experience and not solely on a sample whose results could be questioned by a new experiment (this famous sample fluctuation).
Finally, Bayesian methods also call the systematic use of the p-value into question, which is specific to each study. Where the frequentist approach is based on a one-time estimate of a parameter, the Bayesian approach consists in relying on a body of knowledge that is already available on the subject of the study (derived from the literature or a pilot study, each remaining subject to sampling fluctuations). This body of knowledge allows the estimation of an a priori distribution of data that are already known, then its combination with the results obtained from the new study conducted in order to obtain an a posteriori distribution which will be used to estimate probabilities and credible intervals. The difficulty with this approach consists in identifying high-quality studies that have been carried out previously on the subject in order to define the a priori distribution, as this impacts the final results to a greater or lesser degree.
3. Inspection by attributes: value and limitations of the standard ISO 2859-1
Inspection by attributes consists in noting the presence or absence of a characteristic for each item. For example, the presence of defects on packaged units.
The standard ISO 2859-1(4) is then seen by many as a standard in terms of sample numbers, but in which cases can it be used? What does it contribute, but especially, what are its limitations?
3.1 Explanation of the standard ISO 2859-1
The standard ISO 2859-1(4) (or its American equivalent ANSI/ASQ Z1.4–2003) is applied to the inspection of continuous series of lots. Depending on lot size, it indicates the size of the sample to be inspected, as well as the criteria to be applied.
But before applying the guidelines of this standard, it is necessary to take a position on a number of points:
- What level of inspection should be chosen? Level II, often used by default, or another level?
- Do we want to implement single, double or multiple sampling?
- What Acceptable Quality Level (AQL threshold) should be chosen?
The choice of AQL is obviously the essential element in setting up an inspection by attributes. It should be established with the greatest vigilance, in accordance with consumer’s risk (in order not to wrongly release lots which would not be acceptable to the consumer) but also in accordance with producer’s risk (are we capable of production at a very high quality level?). In order to establish this AQL, it is essential to consult the consumer’s risks and the producer’s risks given at the end of the standard. It is also possible to rely on efficiency curves which give a more dynamic view of the performance of the inspection plan (curves presenting the probability of acceptance of the lot depending on the percentage of defects in the lot).
For example, in single sampling, normal inspection, for a sample of 125 units (code letter K) and an AQL of 1, the table indicates that it is possible to accept up to 3 defects. From 4 defects, the lot must be rejected. The table of calculated values of efficiency curves for the code letter K indicates the following information:
- For an acceptance probability of 95%, the defect rate in the lot is 1.1%. This means that a lot presenting a defect rate of 1.1 % of will be accepted in 95% of cases.
- For an acceptance probability of 50%, the defect rate in the lot is 2.9%. This means that a lot presenting a defect rate of 2.9 % will be accepted one in every two times.
- For an acceptance probability of 10%, the defect rate in the lot is 5.3%. This means that a lot presenting a defect rate of 5.3 % will be accepted in less than 10% of cases. This figure is also found in the Quality table, Consumer’s risk in normal inspection.
Of course the quantity of defects in the lots is not known. But this efficiency curve provides us with essential information: between defect rates of 1.1% and 5.3 %, there will be uncertainty as to whether or not the lot will be accepted, and the lot will generally be rejected if it presents more than 5.3% of defects. Given this information, it is a question of knowing whether these figures are in agreement with the quality requirements of the process.
It should be noted that the severity level of the inspections should also be taken into account. When tests in normal inspection show an insufficient quality level, it is necessary to switch to tightened inspection. The rules for changing severity levels form an integral part of the sampling procedures, and are obligatory.
3.2 Limitations to the application of this standard
During equipment qualification operations or process validation (validation of packaging, production of the pharmaceutical form…), it is sometimes necessary to demonstrate that the equipment (or the process) is capable of producing units that display a low number of defects. This standard, though very informative, is not a recommended tool for determining the sample number which will prove that the quality level is that expected.
The first reason is linked to the scope of this standard: it specifies sampling for the acceptance or non-acceptance of lots, during inspection by attributes of a continuous series of lots. This standard is not initially suitable for isolated lots, even if its use is tolerated by consulting efficiency curves.
In addition, we should be aware that the standard “accepts” defects: the acronym AQL refers to an Acceptable Quality Level. Sometimes, some manufacturers choose to position themselves at “the most severe” inspection level. In practice, this translates as an inspection of 2,000 samples with an AQL set at 0.01 and rejection of the lot if there is one defect. If on the contrary the manufacturer chooses to accept the lot, this means that they judge it acceptable to observe 1 defect in 10,000 items on average. In the context of a qualification or validation operation, this position is disputable. It would in fact be more appropriate to estimate the proportion of defects in the lot, and to set an acceptable limit depending on process performance, quality requirements, and internal or external expectations.
3.3 Then what should be done? Measurement of process performance
The approach proposed below is a conservative approach that can be selected.
Preliminary tests are necessary in order to understand potential variations in performance measurement and in this way to judge the current level of control. Once again, assessment of process performance involves determining how many samples will be needed to judge performance. Confidence intervals are again a good tool to meet this objective. It is in fact possible to use the conservative confidence interval formula of Clopper and Pearson (5)
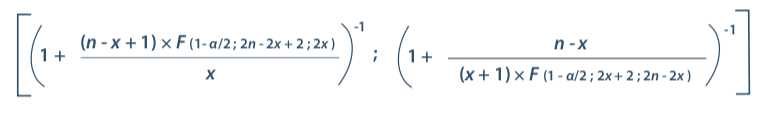
Where:
n : total number of values
x : number of positive responses
α : probability of error
F : Fisher’s law
For example, let us consider an automatic inspection machine with a manufacturer-guaranteed detection rate of over 90%.
Are 100 samples enough to test the machine? The two-sided 90 % confidence interval at 95 % is [82,4% ; 95,1%]. This means that if we carry out tests on 100 samples several times, the proportions will generally be found between 82.4 % and 95.1 %. If a percentage of over 95.1 % is obtained, this means that the detection rate is greater than 90.0 % (with the risk of being mistaken in 2.5 % of cases). Conversely, if a percentage of below 82.4 % is obtained, this this means that the detection rate is below 90 % (with the risk of being mistaken in 2.5% of cases).
So, if 100 defective samples are tested, the acceptability criterion may be to obtain at least 96 detected defective units, in order to guarantee a detection rate of 90%. If this criterion appears too restrictive, it is of course possible to increase the sample size, as that reduces the confidence interval, and makes the criterion more accessible.
Conclusion
Sample size is often a central question in statistical studies. To set up a relevant and appropriate study, the objective must necessarily be clearly formulated, then the structure of the experimental plan which may be applied must be defined. Subsequently the notion of size can be addressed.
Whether the parameter measured is qualitative or quantitative, statistical tools (such as confidence intervals or power, amongst others) ensure that the sample size chosen will meet the objective with a known risk. These statistical tools must be understood to be used wisely. Each statistical test has a precise field of application, and must be used in this context.
As with all tools, to be used and effective they must be used in compliance with their objectives and in line with their conditions of application; but it is also necessary that the person who uses them brings their expertise, know-how and knowledge. So it is the combination of the skills of the user and the adequacy of the tool which will make the study pertinent.
Thanks to all who contributed to the writing of this article: Marine Ragot, Marine Dufournet, Francoise Guerillot-Maire, Florian Kroell, Laura Turbatu, Francois Conesa.
Share Article


Catherine TUDAL – SOLADIS
ctudal@soladis.fr
Bibliography
(1) “International standard for the quality management of medical devices” ISO 13485, April 2016
(2) “Logique et Calcul – Le hasard géométrique n’existe pas !” – Pour la science – No. 341 March 2006
(3) “Pvalues, the ‘gold standard’ of statistical validity, are not as reliable as many scientists assume” Nature, 13 February 2014
(4) “Sampling procedures for inspections by attributes” NF ISO 2859-1, April 2000
(5) “Statistical Intervals A Guide for Practitioners” Gérald J. HAHN and William Q. MEEKER, 1991
