


Summary
- Outsourcing bioproduction of biomedicines in France
- Outsourcing supplier audits: The keys to success
- Selecting container closure components with confidence: A data-driven approach to CCI
- The Art of Understanding Language: The Evolution of Natural Language Processing
- Microbial Monitoring RABS Gloves: Unravelling the Implications of Directional Use
- General Considerations on Bacterial Endotoxins & USP Approach to Developing GC <86> Bacterial Endotoxins Test Using Recombinant Reagents
- Bacterial Spore Formers in Disinfectant Efficacy Testing
- Avoiding product oxidation by H2O2 in isolators. It all depends on the right analyses!
The Art of Understanding Language: The Evolution of Natural Language Processing
Natural Language Processing (NLP) is a discipline whose goal is to give machines the ability to understand and use human language in all its forms. This goal is extremely difficult to achieve due to the complexity of human language, which is characterized not only by the words used but also by the context in which they are used or the intonation employed. Therefore, machines must be capable of understanding spatial reasoning, actions and their effects, emotions, intentions, and social conventions to identify, for example, homonyms (such as for the French word “vers”: “vers” meaning “towards” (direction), “vers” also meaning a verse of poetry, “vers” also meaning “earthworms”).

NLP is at the intersection of several fields: linguistics, computer science, and artificial intelligence. It includes several subsets: Natural Language Understanding (NLU) concerning the understanding of human language (written or spoken) by the machine and Natural Language Generation (NLG) concerning the generation of language by machines.
NLP challenges: ambiguity, common knowledge, creativity, diversity of language(1)
1.The importance of NLP in our daily lives
In our daily lives, NLP is everywhere: in smartphone voice assistants, in identifying emails as spam, in predictive text for writing messages or emails, translator tools, or even chatbots with generative capacities such as ChatGPT. NLP is also used by Google to improve the results of its search engine or by Facebook to detect and filter hateful content(2).
2.NLP history
After World War II, a key challenge was to develop a machine capable of automatically translating Russian into English. In 1954, researchers at Georgetown University designed a machine using six grammatical rules and 250 lexical items. However, this rule-based approach was limited and lacked flexibility, as illustrated by an unexpected translation of ‘the spirit is willing, but the flesh is weak’ into ‘the vodka is agreeable, but the meat is spoiled’.
During the 1950s, Alan Turing proposed the concept of a “universal machine” that mimics human intelligence, introducing the Turing test(3). Researchers, such as Noam Chomsky, questioned the rule-based approach to NLP, prompting the development of formal language theory to explain the syntax and semantics of natural language(4) .In the 1960s and 70s, NLP focused on systems based on more concrete rules (capable of capturing specific aspects of natural language), known as symbolic NLP(5), leading to the development of the first syntactic parsing algorithms. Among others, Joseph Weizenbaum created ELIZA, a rule-based chatbot that simulated a conversation with a psychotherapist(6).
Between 1980 and 1990, the work of Hector Levesque contributed to the development of NLP, creating systems that captured the relationships between concepts in natural language and developing ontologies (formal representations of domain knowledge). Probabilistic statistical models emerged, taking advantage of computing advances to automatically learn linguistic rules, improving entity recognition and sentiment analysis (identifying subjective elements in a text to discern the opinion expressed by the author)(7).
The development of the Internet and search engines, particularly Google in the 1990s and 2000s, significantly improved the performance of algorithms. The approach of these search engines was to combine statistical models such as Naive Bayes classification or Support Vector Machine with rules or “feature functions” (small programs that help detect certain characteristics: keywords, linguistic patterns, syntactic structure, named entities, etc.) that Google engineers would regularly update to improve the relevance of the results. During this period, programming tools such as NLTK (Natural Language Toolkit) and spaCy emerged, allowing for the development of more effective NLP models.
Since the 2000s, deep learning models have emerged, using artificial neural networks (functioning similarly to the human brain) to create vector representations of words called “embeddings”(8). From 2010 onwards, NLP has seen rapid advances with the development of deep learning. Large Language Models (LLMs) based on different architectures, such as Recurrent Neural Networks (RNNs)(9), Convolutional Neural Networks (CNNs)(10), or Recursive Neural Networks (RvNNs)(11), are used for tasks involving the understanding and generation of human language.
Recurrent Neural Networks (RNNs) are specially designed for the sequential processing required during language processing and to retain in memory what has been previously processed. This type of model performs well in many NLP tasks such as text classification or translation(12) but is not suitable when the input text is long. To overcome this limitation, it is possible to use Long Short-Term Memory (LSTM) models, which retain only the important information needed to solve the task. Attention mechanisms are introduced into the models, which significantly improve performance for translation and text summarization.
In the article ‘Attention is All You Need’ written by Vaswani et al(13), the authors describe two major advancements:
- the importance of attention mechanisms that allow for selectively focusing on different parts of a sequence.
- the introduction of Transformer models, which are still widely used today (sequence-to-sequence processing models that involve attention mechanisms to learn the relationships between words and sentences). Upon its release, the Transformer model achieved superior performance compared to previous models on a variety of NLP tasks.
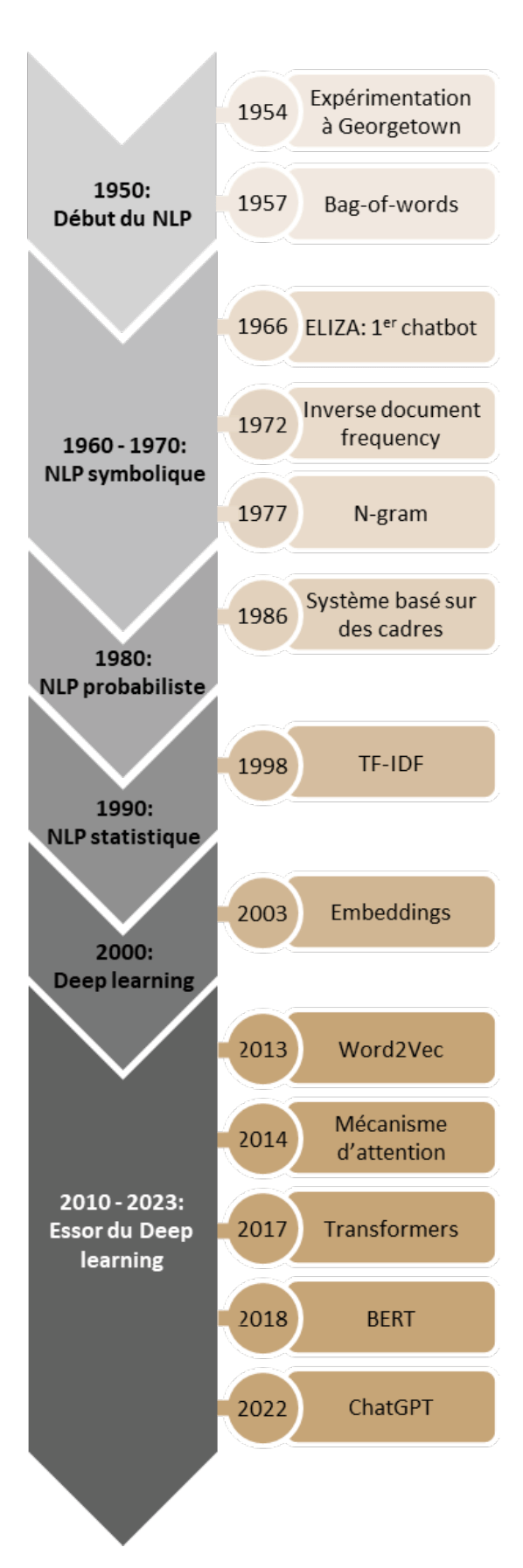
In 2018, Google introduced the Bidirectional Encoder Representations from Transformers or BERT model(14), a bidirectional pre-trained model that has since been adapted to the French language with CamemBERT and FlauBERT. Since 2018, numerous deep learning models have been developed, some surpassing previous ones in terms of translation, grammatical correction, and more. Players such as OpenAI have emerged with models like Ada (2020), Curie (2021), Davinci (2022), and more recently ChatGPT. New models led by giants in artificial intelligence are regularly introduced in this field.
3.Basic NLP techniques
3.1 Natural language understanding:
As mentioned previously, NLP also involves linguistics. Indeed, linguistics is important for the understanding of natural language, particularly for understanding the structure of language. Human language is composed of four main elements: phonemes, morphemes and lexemes, syntax, and context.
Phonemes correspond to the smallest unit of sound in a language. Phonological study is particularly important for NLP tasks involving speech comprehension, the transcription of speech to text, or the representation of text in speech.
Morphological or lexical analysis corresponds to the study of the formation and internal structure of words. It is the basis for text tokenization and normalization. The lexicon of a language is the set of words and phrases of that language. A morpheme is the smallest unit of language that has meaning.
Syntactic analysis corresponds to the study of the formation and internal structure of sentences and assigns a function to words (verb, subject, etc.). Using syntactic analysis, sentences are broken down into their grammatical constituents and take into account relationships between words according to precise rules. There is a differentiation between the subject and the object of the sentence.
The fourth fundamental element of human language is context, which gives a particular meaning to a sentence. Context involves semantic analysis and pragmatic analysis. Semantic analysis corresponds to the study of the meaning of text based on the logical structure of the sentence and grammatical rules outside of context. Pragmatic analysis, on the other hand, studies the meaning that is communicated in a particular context.
3.2 Basic NLP techniques
At the foundation of NLP, several techniques are fundamental for both traditional methods and deep learning-based methods. We can differentiate between techniques for processing raw text and techniques for text representation.
Techniques for preparing a raw text include:
- Segmentation, which refers to techniques for separating written text into meaningful units such as words, sentences, or topics. It is an essential step in many NLP tasks such as summarization, translation, sentiment analysis (enthusiasm, apathy, discontent, etc.). Currently, several segmentation methods can be used, based on rules (for example, the presence of punctuation), as well as statistical methods or deep learning approaches.
- Tokenization is a fundamental step in language processing that involves breaking down text into small units called tokens. Tokens can be words, subwords, or characters. Tokens are used to prepare the vocabulary of the text, meaning a set of unique tokens. This vocabulary will be used for bag-of-words and TF-IDF approaches, which will be discussed below.
Word tokenization is commonly used. Depending on the separator, different tokens are formed. A major limiting factor is the notion ‘out of vocabulary’ when new words are not in the vocabulary subset. After tokenization, the text can be cleaned up before being used in machine learning algorithms. A cleaning step includes the removal of stopwords, such as “the”, which have no informative value but are frequent. Removing stopwords allows the algorithms to concentrate on the words that define the meaning of the text. For some applications, such as translators, stopwords are not removed.
Subsequently, the text can be normalized with techniques such as stemming or lemmatization. Stemming retains the root of the word by removing prefixes and suffixes but does not consider semantic relationships. For example, “running” and “runner” might both be reduced to “run”. Lemmatization represents words in their canonical form, using a dictionary that matches these forms to real words. These cleaning steps are useful in some cases as they lighten the text and speed up calculations such as spam detection), but for certain applications, stopwords are retained to enable a better understanding of the meaning of sentences.
3.3 Text representation techniques
Once the text has been prepared using the previously described steps, it needs to be transformed into a numerical representation that machines can understand. Over time, different methods have been developed to create these text representations. These representations correspond to vectors that more or less successfully capture the linguistic properties of the text they represent.
As early as 1957, the “bag of words” technique made its appearance in the context of information retrieval. It is based on the counting of words or the frequency of tokens. With this method, each document is represented by a vector of the size of the vocabulary present in the document, and the occurrence of each word is noted. The text is represented by an NxN matrix where N is the number of unique tokens in the text. Since this matrix contains mostly zeros, the matrices are rather sparse. As the size of the vocabulary determines the size of the matrix, this method requires large memory capacities when the documents contain a rich vocabulary. Moreover, if a document containing a token that was not presented during training is submitted to the model, this token is not recognized (the “out of vocabulary” problem). Another disadvantage of this approach is that the semantic meaning of the text is not captured(15).
In 1972, Karen Spärck Jones introduced a new approach that involves weighting the importance of a token by using the inverse of its frequency (IDF – inverse document frequency) within the document(16). The combination of the bag-of-words approach, which considers the frequency of tokens (TF), with the IDF approach corresponds to the TF-IDF (Term Frequency – Inverse Document Frequency) method that has been used in machine learning since 1998(17). This approach thus allows to measure the relevance of tokens in a document and significantly improves the performance obtained. However, it still does not capture the semantic meaning of words or enable the understanding of context.
Another way to represent text is to consider a word and the words that accompany it, the n-gram language model, as described by John Rupert Firth in 1957(18). An n-gram is a sequence of n words; the model predicts the probability of a word based on the preceding word(s). This model thus takes context into account and allows to treat each word as a probability of occurrence based on the preceding text.
As of the 2000s, a new family of techniques called embeddings emerged to create distributed numerical representations of text(19). In such embeddings, words are represented in a probabilistic space where their meaning brings them closer in terms of statistical distances. With these techniques, words are represented by dense vectors of fixed size in a high-dimensional space (multiple components). The vector associated with each word takes into account the context in which it appeared in the text, thus providing a representation that accounts for the grammatical and semantic properties of words.
The first model used for embedding is called Word2Vec. Developed by researchers at Google, Word2Vec was trained with nearly 100 billion words from Google News. Word2Vec was quickly followed by GloVe developed by researchers at Stanford (Pennington et al.) (20)and FastText developed by researchers at Facebook (Bojanowski et al.)(21), both trained notably with Wikipedia articles. Embeddings from Language Models (ELMo) also figure among embedding models (22). In this case, the vectors representing words are calculated by a two-layer bidirectional language model (biLM).
3.4 NLP applications
Below are some applications of NLP:
- Automatic translation: automatic translation systems, such as Google Translate or DeepL, use NLP to translate texts from one language to another. Some translators are also capable of automatically detecting the language of the input text.
- Automatic text generation: LLMs can generate coherent and contextually relevant text based on a given prompt, opening possibilities for creative writing, blog content, etc. Text generation is also used in virtual assistants and chatbots.
- Sentiment analysis: this is a process of classifying the emotional intent of a text. Typically, the input to a sentiment classification model is a piece of text, and the output is the probability that the expressed sentiment is positive, negative, or neutral. Sentiment analysis is used to classify customer comments on various online platforms, for example.
- Topic modeling: this is a text analysis technique used to discover latent patterns or themes in a corpus of documents. The goal of topic modeling is to automatically extract topics or themes from large sets of unlabeled texts, without a human having to specify these themes beforehand. This is particularly useful for recommending documents based on an initial document and helping to detect trends.
- Text classification: the most common use case is spam detection. This is a binary classification problem that is widespread in the field of NLP, with the goal of classifying emails as spam or not. Spam detectors take as input the text of an email as well as various other subtexts such as the title and the sender’s name. They aim to determine the probability that the email is spam. Email service providers, like Gmail, use such models to improve user experience by detecting unsolicited and unwanted emails and moving them to a designated spam folder.
- Grammatical correction: grammatical error correction models encode grammatical rules to correct the grammar of a text. This is primarily a sequence-to-sequence task, in which a model is trained on an ungrammatical sentence as input and a correct sentence as output. Online grammar checkers like Grammarly and text processing systems like Microsoft Word use these systems to offer a better writing experience to their clients.
- Text summarization: this involves shortening a text to highlight the most relevant information.
- Speech recognition: these are algorithms that can identify the speaker’s voice, convert the spoken words into text, and interpret the underlying meaning. Apple’s Siri and Amazon’s Alexa are tools that use NLP to listen to user requests and find answers. Also, many companies integrate these models into their Customer Relationship Management (CRM) system to improve customer experience.
4.NLP challenges
Challenges of NLP include:
- Complexity: natural languages are inherently ambiguous. The same word or phrase can have multiple meanings or interpretations depending on the context.
- Variability: languages are constantly evolving. New words, expressions, and usages appear regularly.
- Wordplay: puns, metaphors, and idiomatic expressions can be difficult for NLP models to interpret.
- Human errors: texts written by humans can contain errors in grammar, spelling, punctuation, etc.
- Connotation and emotion: words and phrases can carry emotional or cultural connotations, which requires a subtle understanding of the meaning and impact of language.
- Abstraction: texts may contain abstractions, generalizations, and complex concepts that require deep and contextual understanding.
- Length and coherence: documents can vary in length, ranging from a few words to long paragraphs or complex texts. NLP models must be capable of maintaining coherence and understanding across variable text lengths.
- Ethics: there is a need to mitigate biases, ensure transparency, and prevent harmful consequences, while ensuring responsible and fair use of technology.
5.The future of NLP
5.1Recent and future NLP developments
Advanced language models like GPT-4, developed by OpenAI(23), have a vast number of parameters (1.7 trillion) and accept tokens as input to be processed in the network. GPT-4 has been a particularly significant language model because it was one of the first large-scale models, enabling it to perform even more advanced tasks such as programming and solving high school-level mathematical problems. The latest version, called InstructGPT, has been fine-tuned by humans to generate responses that are much more aligned with human values and user intentions. Additionally, Google’s latest model, Gemini(24), presents new impressive advancements in language and reasoning.
The Codex tool, based on the GPT-4 model, serves as an assistant to programmers by generating code from natural language inputs. It already powers products such as Copilot for GitHub, a subsidiary of Microsoft, and is capable of creating a basic video game simply by typing instructions. The latest creation from Google’s DeepMind AI lab, for example, demonstrates the critical thinking and logic capabilities required to outperform most humans in programming competitions.
Models like GPT-4 can even be trained on multiple forms of data simultaneously. For instance, OpenAI’s DALL-E 3 is trained on language and images to generate high-resolution renderings of scenes or imaginary objects simply from text prompts. Other competitors like Midjourney v6(25) and Stable Diffusion XL(26) have also been created and made available as digital tools to the community.
Below is the result of the following instruction with different algorithms: “Imagine a scene capturing the essence of AI and creativity for an article on the advancements of NLP. Stage a digital brain with neural networks, surrounded by a screen displaying varied images, ranging from surrealism to futuristic landscapes, reflecting the creative potential of <model’s name >. Use a background that evokes a digital matrix, symbolizing the underlying technology.”

5.2Possible new NLP applications
New applications are emerging for analyzing PDF-type documents. For example, the tool chatpdf(27) allows you to upload a PDF file and chat with the document. This tool is used, for example, to browse scientific documents, academic articles, and books to quickly obtain information.
There are also tools that facilitate bibliographic research. Among these tools, we find:
- Consensus(29): an AI tool used to analyze peer-reviewed research and extract the main conclusions from each.
- Scite(30): an AI tool that allows users to find the right sources for writing scientific articles.
- Elicit(31): a tool that is capable of locating relevant articles and extracting information without the need for matching specific keywords in the query. This AI tool can assist with various exploration exercises, including conceptualization, synthesis, and text ordering, as well as synthesizing central questions for report writing.
- ResearchRabbit(32): called by its founders “the Spotify of research,” Research Rabbit allows users to add academic articles to “collections”. These collections help the software understand the user’s interests, leading to new relevant recommendations. ResearchRabbit also allows users to visualize the network of articles by authors and co-authors in the form of graphs, so users can follow the work of a single subject or author and dive deeper into their research.
- Scholarcy(33) or PaperDigest(34): these are similar tools that summarize academic articles and highlight the most important parts for the reader. They also allow to quickly and easily determine whether an article is relevant or not.
Additionally, new applications are emerging such as multi-agent systems: these consist of a set of autonomous agents interacting with each other to achieve specific goals. Each agent in a multi-agent system is an autonomous entity with its own ability to perceive, make decisions, and act.
Currently, there are several AI systems of this type, including:
- Autogen by Microsoft(35): this is an AI that simplifies the orchestration, optimization, and automation of workflows for LLMs. It offers customizable and conversational agents that leverage the strongest and most advanced capabilities of LLMs, such as GPT-4, while addressing their limitations by interacting with humans and tools and having conversations between multiple agents via automated chat.
- Mixtral (sparse mixture-of-experts)(36): this is a model based solely on the decoder part where, at each layer, for each token, a router chooses two out of eight available groups of parameters (named “experts”) to analyze the token and combine the results. This technique allows to reduce the number of parameters in a model while controlling cost and latency. Indeed, this type of model only uses a fraction of the total parameters defined per token. For example, Mixtral has 46.7 billion total parameters and uses only 12.9 billion parameters per token.
Additionally, multimodal models are emerging. Examples include GPT-4 and Gemini Pro. These are AIs that are capable of understanding, processing, and integrating multiple types of data or input signals (text, audio, image, video, computer code).
Among the use cases, there are, for example:
- “Text to image”: from a text, the AI tool is capable of generating an image
- “Text to music”: from a text, the AI tool is capable of generating music
- “Image to text”: from an image, the AI tool provides a description of the elements represented
Finally, NLP models are being developed for specific domains (legal, regulatory, medical, scientific, etc.). There are websites that list all these variants of models, such as HuggingFace(37) or, very recently, GPTStore(38).
To conclude, companies like Meta aim to develop reliable and responsible generative AI tools (Purple Llama)(39). These Ais tools are tested by teams to ensure that they do not produce, for example, hateful or unethical content.
6.Conclusion
This article sheds light on a fascinating domain of AI: NLP. We dove into the history of NLP, from its beginnings in the 1950s to its current state, tracing the constant evolution of concepts and technologies that have shaped today’s most sophisticated models. Throughout this evolution, a plethora of text representation and analysis techniques have been meticulously developed.
Today, NLP permeates various sectors with applications as diverse as text analysis and synthesis, translation, information retrieval in documents, classification, and even content generation. This rapid ascent is propelled by the parallel evolution of hardware tools dedicated to training models by leveraging new technologies.
Future developments will include multimodal systems that are not limited to text but also encompass the generation of images, sounds, and videos. Lastly, the latest advancements focus on models that are more resource-efficient without compromising performance. An exciting era is unfolding in the field of NLP, with ever-broadening horizons and innovative possibilities.
Share


Virginie BRIFFAUD
![]()

Enrico PERSPICACE
![]()

Mehdi Olivier DOUBIANI
![]()
References
- S. Vajjala, B. Majumder, A. Gupta & H. Surana. « Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems », 2020, Oreilly & Associates Inc, ISBN-10 : 1492054054.
- « A complete guide to Natural Language Processing », DeepLearning.AI, https://www.deeplearning.ai/resources/ natural-language-processing/
- A. M. Turing, « Computing Machinery and Intelligence », 1950, Mind 49: 433-460.
- Jacob Eisenstein, « Introduction to natural language processing », 2019, Adaptive Computation and Machine Learning series, ISBN : 9780262042840.
- « A brief history of NLP », World Wide Technology, https://www.wwt.com/blog/a-brief-history-of-nlp
- A. Grechanyuk, « A short explanation of the history of the natural language models », 2023, https://www.linkedin.com/ pulse/short-explanation-history-natural-language-models-anton-grechanyuk/
- R. Brachman, H. Levesque, « Readings in Knowledge Representation », 1985, Los Altos, Calif. : M. Kaufmann Publishers
- Y. LeCun, Y. Bengio & G. Hinton, « Deep learning », Nature, 2015, 521, 436–444
- K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk & Y. Bengio, « Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation », 2014, https://arxiv.org/abs/1406.1078
- Y Xiao, K Cho, « Efficient Character-level Document Classification by Combining Convolution and Recurrent Layers », 2016, https://arxiv.org/abs/1602.00367
- A. Sperduti & A. Starita, « Supervised neural networks for the classification of structures », 1997, IEEE Transactions on Neural Networks, 8, 714-735, doi: 10.1109/72.572108
- A. Kaparthy, « The Unreasonable Effectiveness of Recurrent Neural Networks », 2015, https://karpathy.github. io/2015/05/21/rnn-effectiveness/
- D. Bahdanau, K. Cho, Y. Bengio, « Neural Machine Translation by Jointly Learning to Align and Translate », 2014, https:// arxiv.org/abs/1409.0473
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, « Attention Is All You Need », 2017, https://arxiv.org/abs/1706.03762
- J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, « BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding », 2018, https://arxiv.org/abs/1810.04805
- I. Sharaf, « Introduction to Natural Language Processing (NLP) », 2019, https://towardsdatascience.com/introduction- to-natural-language-processing-nlp-323cc007df3d
- K. Spärck Jones, « A statistical interpretation of term specificity and its application in retrieval », 1972, Journal of Documentation, 28, 11-21
- T. Joachims, « Text categorization with Support Vector Machines: Learning with many relevant features ». In: Nédellec, C., Rouveirol, C. (eds) Machine Learning: ECML-98. ECML 1998. Lecture Notes in Computer Science, 1998, 1398, 137-142
- J. Firth, « A Synopsis of Linguistic Theory, 1930-55 », 1957, Linguistics
- T. Mikolov, K. Chen, G. Corrado & J. Dean, « Efficient Estimation of Word Representations in Vector Space », 2013, https://arxiv.org/ abs/1301.3781
- J. Pennington, R. Socher, C. D. Manning, « GloVe: Global Vectors for Word Representation », https://nlp.stanford.edu/pubs/glove.pdf 22.
- A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou & T. Mikolov, « FastText.zip: Compressing text classification models », 2016, https://arxiv.org/abs/1612.03651
- M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee & L. Zettlemoyer, « Deep contextualized word représentations », 2018, https://arxiv.org/abs/1802.05365
- GPT-4, https://openai.com/chatgpt
- Google Gemini, https://openai.com/chatgpt
- Midjourney v6, https://mid-journey.ai/midjourney-v6-release/
- StableDiffusion XL, https://stablediffusionweb.com/StableDiffusionXL
- Chatpdf, https://www.chatpdf.com/
- PDFGear, https://www.pdfgear.com/fr/
- Consensus, https://consensus.app/
- Scite, https://scite.ai/
- Elicit, https://elicit.com/
- ResearchRabbit, https://www.researchrabbit.ai/
- Scholarcy, https://www.scholarcy.com/
- PaperDigest, https://www.paperdigest.org/
- « AutoGen: Enabling next-generation large language model applications », 2023, https://www.microsoft.com/en-us/research/blog/autogen-enabling-next-generation-large-language-model-applications/
- Mixtral, https://www.microsoft.com/en-us/research/blog/autogen-enabling-next-generation-large-language-model- applications/
- HuggingFace, https://huggingface.co/
- GPTStore, https://gptstore.ai/plugins
- Purple Llama, https://ai.meta.com/llama/purple-llama/
