


Avril 2024
La Vague n°81
Externalisation des activités – Maitrise de la contamination
Sommaire
- Sous-traitance de la bioproduction des biomédicaments en France
- Externalisation des audits fournisseurs : Les clés de la réussite
- Selecting container closure components with confidence: A data-driven approach to CCI
- L’art de comprendre le langage : l’évolution du traitement automatique du langage
- Microbial Monitoring RABS Gloves: Unravelling the Implications of Directional Use
- General Considerations on Bacterial Endotoxins & USP Approach to Developing GC <86> Bacterial Endotoxins Test Using Recombinant Reagents
- Bacterial Spore Formers in Disinfectant Efficacy Testing
- Avoiding product oxidation by H2O2 in isolators. It all depends on the right analyses!
L’art de comprendre le langage : l’évolution du traitement automatique du langage
Le traitement automatique du langage ou Natural Language Processing (NLP) est une discipline qui a pour objectif de donner la capacité aux machines de comprendre et d’utiliser le langage humain sous toutes ses formes. Cet objectif est extrêmement difficile à atteindre du fait de la complexité du langage humain qui se caractérise non seulement par les mots utilisés mais également par le contexte dans lequel ils sont utilisés ou l’intonation employée. Il faut donc que les machines soient capables d’avoir une compréhension des raisonnements spatiaux, des actions et de leurs effets, des émotions, des intentions et des conventions sociales pour identifier, par exemple, des homonymes (“vers” une direction, “vers” de poésie, “vers” de terre).

Le NLP est au croisement de plusieurs domaines : la linguistique, l’informatique et l’intelligence artificielle. Il comprend plusieurs sous-ensembles : le NLU (Natural Language Understanding) pour ce qui concerne la compréhension du langage humain (écrit ou parlé) par la machine et le NLG (Natural Language Generation) pour ce qui concerne la génération de langage par les machines.
Challenge du NLP: ambiguïté, connaissances communes, créativité, diversité des langages(1).
1. Importance du NLP dans notre vie quotidienne
Dans notre vie quotidienne, le NLP est omniprésent que ce soit avec les assistants vocaux de smartphones, l’identification des emails comme étant des spams, l’écriture intuitive pour la rédaction de messages ou d’emails, les traducteurs mais aussi les chatbots avec à présent les modèles génératifs tel que ChatGPT. Le NLP est également utilisé par Google pour améliorer les résultats de son moteur de recherche ou par Facebook pour détecter et filtrer les contenus haineux (2).
2. Historique du NLP
Après la seconde guerre mondiale, l’enjeu fut de développer une machine permettant de traduire automatiquement le russe en anglais. En 1954, les chercheurs de Georgetown ont conçu une machine utilisant six règles grammaticales et 250 éléments lexicaux. Cependant, cette approche basée sur des règles était limitée et manquait de flexibilité, comme illustré par une traduction inattendue de ‘the spirit is willing, but the flesh is weak’ en ‘the vodka is agreable, but the meat is spoiled‘.
Pendant les années 1950, Alan Turing proposa le concept d’une “machine universelle” imitant l’intelligence humaine, introduisant le test de Turing (3). Des chercheurs, tels que Noam Chomsky, remirent en question l’approche du NLP basée sur des règles, incitant à développer la théorie du langage formel pour expliquer la syntaxe et la sémantique du langage naturel (4).
Dans les années 60-70, le NLP se concentra sur des systèmes basés sur des règles plus concrètes (permettant de capturer des aspects spécifiques du langage naturel), appelées NLP symbolique (5), conduisant au développement des premiers algorithmes d’analyse syntaxique. Entre autres, Joseph Weizenbaum créa ELIZA, un chatbot basé sur des règles simulant une conversation avec un psychothérapeute(6).
Entre 1980 et 1990, les travaux de Levesque contribuèrent au développement du NLP, créant des systèmes capturant les relations entre les concepts en langage naturel et développant des ontologies (représentations formelles des connaissances du domaine). Des modèles statistiques probabilistes émergèrent, profitant des avancées informatiques pour apprendre automatiquement des règles linguistiques, améliorant la reconnaissance d’entités et l’analyse des sentiments (repérage des éléments subjectifs dans un texte afin de dégager l’opinion exprimée par l’auteur).
Le développement d’Internet et des moteurs de recherche, notamment Google dans les années 1990-2000, améliora considérablement les performances des algorithmes. L’approche de ces moteurs de recherches était de combiner les modèles statistiques tels que la classification naïve bayésienne ou le Support Vector Machine avec des règles ou “feature functions” (petits programmes aidant à détecter certaines caractéristiques : mots-clés, motifs linguistiques, structure syntaxique, entités nommées, etc.) que les ingénieurs de Google mettaient à jour régulièrement afin d’améliorer la pertinence des résultats. Durant cette période, des outils de programmation tels que NLTK (Natural Language Toolkit) et spaCy émergèrent, permettant le développement de modèles de NLP plus performants.
Depuis les années 2000, les modèles de deep learning font leur apparition, utilisant des réseaux de neurones artificiels (fonctionnement similaire au cerveau humain) pour créer des représentations vectorielles des mots appelées “embeddings” (8). À partir de 2010, le NLP connaît des avancées rapides avec le développement du deep learning. Des LLM (Large Language Models) basés sur différentes architectures, tels que les réseaux de neurones récurrents (RNN)(9), convolutifs (CNN)(10), ou récursifs (RvNN)(11), sont utilisés pour des tâches de compréhension et de génération de langage humain.
Les réseaux de neurones récurrents (RNN) sont spécialement conçus pour le traitement séquentiel nécessaire lors du traitement du langage et garder en mémoire ce qui a été préalablement traité. Ce type de modèle est performant dans de nombreuses tâches de NLP telles que la classification de texte ou la traduction(12) mais n’est pas adapté lorsque le texte d’entrée est long. Pour pallier ce défaut, il est possible d’utiliser les modèles LSTM (Long – Short Term Memory) qui ont la particularité de ne garder en mémoire que les informations importantes pour résoudre la tâche. Des mécanismes d’attention sont introduits dans les modèles(13) ce qui permet d’améliorer significativement les performances pour la traduction et le résumé de textes.
Dans l’article ‘Attention is all you need’ écrit par Vaswani et al. (14), les auteurs décrivent deux avancées majeures :
- l’importance des mécanismes d’attention qui permettent de focaliser de manière sélective sur différentes parties d’une séquence,
- les modèles de types Transformers (15) encore très utilisés aujourd’hui (modèles de traitement de séquence à séquence faisant intervenir des mécanismes d’attention pour apprendre les relations entre les mots et les phrases).
Dès sa sortie, le modèle Transformer a obtenu des performances supérieures aux modèles précédents sur une variété de tâches de NLP.
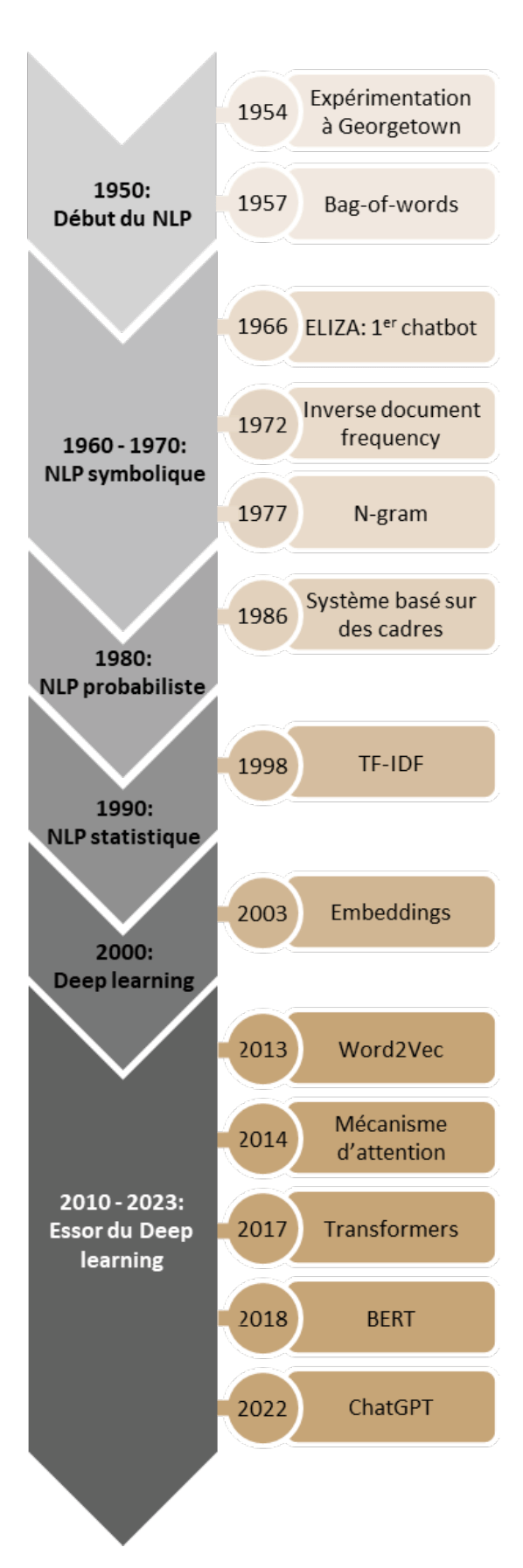
En 2018, Google propose le modèle BERT (Bidirectional Encoder Représentations from Transformers), un modèle bidirectionnel pré-entraîné qui a depuis été adapté à la langue française avec CamemBERT et FlauBERT. Depuis 2018, de nombreux modèles de deep learning ont été développés, certains surpassant les précédents en termes de traduction, correction grammaticale, etc.
Des acteurs tels qu’OpenAI ont émergé avec des modèles comme Ada (2020), Curie (2021), Davinci (2022), et plus récemment Chat GPT. Actuellement, de nouveaux modèles sont régulièrement introduits dans ce domaine dirigé par des géants de l’intelligence artificielle.
3. Techniques de base du NLP
3.1 La compréhension du langage naturel
Comme mentionné dans l’introduction, le NLP fait également intervenir de la linguistique. En effet, cette dernière est importante pour la compréhension du langage naturel notamment pour comprendre la structure du langage. Le langage humain est composé de quatre éléments principaux : les phonèmes, les morphèmes et lexèmes, la syntaxe et le contexte.
Les phonèmes correspondent à la plus petite unité de son dans un langage. L’étude phonologique est particulièrement importante pour les tâches de NLP impliquant la compréhension de la parole, la transcription de la parole en texte ou la représentation du texte en parole.
L’analyse morphologique ou lexicale correspond à l’étude de la formation et de la structure interne des mots. Elle est à la base de la tokenisation et de la normalisation du texte. Le lexique d’une langue est l’ensemble des mots et des phrases de cette langue. Un morphème est la plus petite unité de langage possédant une signification.
L’analyse syntaxique correspond à l’étude de la formation et de la structure interne des phrases et attribue une fonction aux mots (verbe, sujet…). En utilisant l’analyse syntaxique, les phrases sont séparées en ses constituants grammaticaux et prend en compte des relations entre les mots selon des règles précises. Il y a une différenciation entre le sujet et l’objet de la phrase.
Le quatrième élément fondamental du langage humain est le contexte qui va permettre de donner un sens particulier à une phrase. Le contexte fait intervenir une analyse sémantique et une analyse pragmatique. L’analyse sémantique correspond à l’étude de la signification du texte basée sur la structure logique de la phrase et les règles grammaticales en dehors du contexte. L’analyse pragmatique quant à elle étudie le sens qui est communiqué dans un contexte particulier.
3.2 Techniques de base du NLP
A la base du NLP, plusieurs techniques sont fondamentales aussi bien pour les méthodes traditionnelles que pour les méthodes basées sur du deep learning. Nous pouvons différencier les techniques de traitement de texte brut et les techniques de représentation de texte.
Parmi les techniques de préparation du texte brut, nous pouvons citer :
- La segmentation qui fait référence à des techniques de séparation de texte écrit en unités ayant du sens telles que les mots, les phrases ou les sujets. C’est une étape essentielle dans beaucoup de tâches de NLP comme faire des résumés, la traduction, l’analyse de sentiments (enthousiasme, apathie, mécontent, etc.). Actuellement, plusieurs méthodes de segmentation peuvent être utilisées, basées sur des règles (par exemple la présence de ponctuation), avec des méthodes statistiques ou de deep learning.
- La tokenisation qui est une étape fondamentale pour le traitement du langage consistant à séparer le texte en petites unités appelées tokens. Les tokens peuvent être soit des mots, des sous-mots ou des caractères. Les tokens sont utilisés pour préparer le vocabulaire du texte c’est-à- dire à un set de tokens unique. Ce vocabulaire sera utilisé pour les approches bag-of-word et TF-IDF que nous verrons plus tard.
La tokenisation en mots est couramment utilisée. Selon les séparateurs, différents tokens sont formés. Une limitation majeure est le ‘out of vocabulary’ lorsque de nouveaux mots ne sont pas dans le vocabulaire. Après la tokenisation, le texte peut être nettoyé avant d’être utilisé dans les algorithmes de machine learning. Une étape de nettoyage inclut la suppression des stopwords, comme “le” et “la”, qui n’ont pas de valeur informative mais sont fréquents. La suppression des stopwords permet aux algorithmes de se concentrer sur les mots définissant la signification du texte. Pour certaines applications comme la traduction, les stopwords ne sont pas supprimés.
Ensuite, le texte peut être normalisé avec des techniques de stemming ou de lemmatisation. Le stemming conserve la racine du mot en supprimant préfixes et suffixes, mais ne considère pas les relations sémantiques. Par exemple, “université” et “universitaire” deviennent “univers”. La lemmatisation représente les mots sous leur forme canonique, en utilisant un dictionnaire pour correspondre à des mots réels.
Ces étapes de nettoyage sont utiles dans certains cas (allègent le texte, accélèrent les calculs comme la détection de spams), mais pour certaines applications, les stopwords sont conservés pour mieux comprendre la signification des phrases.
3.3 Les techniques de représentation de texte
Une fois le texte préparé en utilisant les étapes précédemment décrites, le texte a besoin d’être transformé dans une représentation numérique compréhensible par les machines. Au cours du temps, différentes méthodes ont été développées afin de créer ces représentations de textes. Ces représentations correspondent à des vecteurs qui vont plus ou moins réussir à capturer les propriétés linguistiques du texte qu’ils représentent.
Dès 1957, la technique du “bag of words” (sac de mots) a fait son apparition dans le contexte de la recherche d’informations. Elle est basée sur le comptage des mots ou fréquence des tokens. Avec cette méthode, chaque document est représenté par un vecteur de la taille du vocabulaire présent dans le document et l’occurrence de chaque mot est notée. Le texte est représenté par une matrice de taille NxN où N est le nombre de tokens unique dans le texte. Comme cette matrice contient majoritairement des zéros, nous parlons de matrices creuses (sparse matrix). La taille du vocabulaire déterminant la taille de la matrice, cette méthode nécessite des grosses capacités de mémoire lorsque les documents contiennent un vocabulaire riche. De plus, si un document contenant un token non présenté lors de l’entrainement est soumis au modèle, ce token n’est pas reconnu (problème du “out of vocabulary“). Un autre désavantage de cette approche est que le sens sémantique du texte n’est pas capturé (16).
En 1972, Karen Spärck Jones introduit une nouvelle approche qui consiste à pondérer le poids du token en utilisant l’inverse de sa fréquence (idf – inverse document frequency) au sein du document (17). La combinaison de l’approche bag-of-words, qui considère la fréquence des tokens (tf ), avec l’approche idf correspond à la méthode Tf-idf (Term-frequency inverse document frequency) utilisée depuis 1998 en machine learning (18). Cette approche permet donc de mesurer la pertinence des tokens dans un document et améliore considérablement les performances obtenues. En revanche, elle ne permet toujours pas de capturer la signification sémantique des mots ou de comprendre le contexte.
Une autre façon de représenter le texte est de considérer un mot et les mots qui l’accompagne comme l’avait mentionné John Rupert Firth en 1977 (19). Pour cela, le premier modèle développé a été celui du modèle de langage n-gram. Un n-gram est une séquence de n mots et le modèle va prédire la probabilité d’un mot en fonction du mot qui précède. Ce modèle prend donc en compte le contexte et permet de traiter chaque mot comme une probabilité d’apparition en fonction du texte qui précède.
A partir des années 2000, une nouvelle famille de techniques appelée embedding a émergé pour créer des représentations numériques distribuées du texte(20). A présent, les mots sont représentés dans un espace probabiliste dans lequel leur sens les rapproche en termes de distances statistiques. Avec ces techniques, les mots sont représentés par des vecteurs denses de taille fixe dans un espace de hautes-dimensions (plusieurs composantes). Le vecteur associé à chaque mot prend en compte le contexte dans lequel il est apparu dans le texte, fournissant ainsi une représentation tenant compte des propriétés grammaticales et sémantiques des mots.
Le premier modèle utilisé pour l’embedding est Word2Vec. Développé par des chercheurs de Google, Word2vec a été entrainé avec près de 100 milliards de mots présents dans les Google news. Word2Vec fut rapidement suivi par Glove développé par des chercheurs de Stanford (Pennington et al.) (21) et FastText développé par des chercheurs de Facebook (Bojanowski et al.) (22), tous deux entrainés notamment avec des articles Wikipédia. Parmi les modèles d’embedding, nous pouvons également citer ELMo (Embeddings from Language Models) (23). Dans ce cas, les vecteurs représentant les mots sont calculés par un modèle de langage bidirectionnel à deux couches (biLM).
3.4 Applications du NLP
Ci-dessous, quelques applications du NLP :
- La traduction automatique : les systèmes de traduction automatique, tels que Google Translate ou DeepL, utilisent le NLP pour traduire des textes d’une langue à une autre. Certains traducteurs sont également capables de détecter automatiquement la langue du texte d’entrée.
- La génération de texte automatique : les Large Language Models (LLMs) peuvent générer un texte cohérent et contextuellement pertinent en fonction d’une invite donnée, ouvrant des possibilités pour l’écriture créative, le contenu des blogs, etc. La génération du texte est également utilisée dans les assistants virtuels et les chatbots.
- L’analyse des sentiments : il s’agit d’un processus de classification de l’intention émotionnelle d’un texte. Généralement, l’entrée d’un modèle de classification des sentiments est un morceau de texte, et la sortie est la probabilité que le sentiment exprimé soit positif, négatif ou neutre. L’analyse des sentiments est utilisée pour classer les commentaires des clients sur diverses plateformes en ligne par exemple.
- Le topic modeling : il s’agit d’une technique d’analyse de texte utilisée pour découvrir des motifs ou des thèmes latents dans un corpus de documents. L’objectif du topic modeling est d’extraire automatiquement des sujets ou des thèmes à partir de grands ensembles de textes non étiquetés, sans qu’un être humain n’ait à spécifier préalablement ces thèmes. Cela permet notamment la recommandation de documents à partir d’un document initial et d’aider à détecter les tendances.
- La classification de texte : le cas d’usage le plus courant est la détection de spams. Il s’agit d’un problème de classification binaire très répandu dans le domaine du NLP, dont l’objectif est de classer les courriels en tant que spams ou non. Les détecteurs de spam prennent en entrée le texte d’un courrier électronique ainsi que divers autres sous-textes tels que le titre et le nom de l’expéditeur. Ils visent à déterminer la probabilité que l’e-mail soit un spam. Les fournisseurs de services de messagerie électronique, comme Gmail, utilisent de tels modèles pour améliorer l’expérience des utilisateurs en détectant les courriels non sollicités et indésirables et en les déplaçant vers un dossier de spam désigné.
- La correction grammaticale : les modèles de correction d’erreurs grammaticales codent des règles grammaticales pour corriger la grammaire d’un texte. Il s’agit principalement d’une tâche de séquence à séquence, dans laquelle un modèle est entraîné sur une phrase non grammaticale en entrée et une phrase correcte en sortie. Les correcteurs grammaticaux en ligne comme Grammarly et les systèmes de traitement de texte comme Microsoft Word utilisent ces systèmes pour offrir une meilleure expérience d’écriture à leurs clients.
- Le résumé de texte : cela consiste à raccourcir un texte pour en faire ressortir les informations les plus pertinentes.
La reconnaissance vocale : il s’agit d’algorithmes pouvant identifier la voix de l’orateur, convertir les mots prononcés en texte et interpréter le sens qui les sous-tend. Siri d’Apple et Alexa d’Amazon sont des outils qui utilisent le NLP pour écouter les demandes des utilisateurs et trouver des réponses. Aussi, de nombreuses sociétés intègrent ces modèles dans leur Customer Relationship Management (CRM) afin d’améliorer l’expérience client.
4. Les défis du NLP
Parmi les défis du NLP, il y a :
- La complexité : les langues naturelles sont intrinsèquement ambiguës. Un même mot ou une même phrase peut avoir plusieurs sens ou interprétations en fonction du contexte.
- La variabilité : les langues évoluent constamment. De nouveaux mots, expressions et usages apparaissent régulièrement.
- Jeux de mots : les jeux de mots, les métaphores et les expressions idiomatiques peuvent être difficilement interprétables par des modèles de NLP.
- Erreurs humaines : les textes écrits par des humains peuvent contenir des erreurs de grammaire, d’orthographe, de ponctuation, etc.
- Connotation et émotion : les mots et les phrases peuvent avoir des connotations émotionnelles ou culturelles, ce qui nécessite une compréhension subtile de la signification et de l’impact du langage.
- Abstraction : les textes peuvent contenir des abstractions, des généralisations et des concepts complexes qui nécessitent une compréhension profonde et contextuelle.
- Longueur et cohérence : les documents peuvent être de différentes longueurs, allant de quelques mots à de longs paragraphes ou des textes complexes. Les modèles NLP doivent être capables de maintenir la cohérence et la compréhension sur des échelles variées.
- Ethique : nécessité d’atténuer les biais, de garantir la transparence et de prévenir les conséquences néfastes, tout en assurant une utilisation responsable et équitable de la technologie.
5. L’avenir du NLP
5.1 Les développements récents et futurs du NLP
Le GPT-4, développé par OpenAI(24), 1.7 trilliards de paramètres en entrée (modèle qui accepte des tokens en entrée pour être traités dans le réseau) et a été un modèle de langage particulièrement important car il a été le premier modèle de langage de grande taille, ce qui lui a permis d’effectuer des tâches encore plus avancées telles que la programmation et la résolution de problèmes mathématiques de niveau lycée. La dernière version, appelée InstructGPT, a été affinée par des humains pour générer des réponses beaucoup plus conformes aux valeurs humaines et aux intentions de l’utilisateur. Enfin, le dernier modèle de Google Gemini(25) présente de nouvelles avancées impressionnantes en matière de langage et de raisonnement.
L’outil Codex, basé sur le modèle GPT-4, sert entre autres comme assistant aux programmeurs en générant du code à partir d’entrées en langage naturel. Il alimente déjà des produits tels que Copilot pour GitHub, la filiale de Microsoft, et il est capable de créer un jeu vidéo de base simplement en tapant des instructions. Le dernier né du laboratoire d’IA DeepMind de Google, par exemple, démontre les capacités de réflexion critique et de logique nécessaires pour surpasser la plupart des humains dans les compétitions de programmation.
Les modèles tels que le GPT-4 peuvent même être entraînés sur plusieurs formes de données en même temps. Par exemple DALL-E 3 d’OpenAI est entraîné sur le langage et les images pour générer des rendus haute résolution de scènes ou d’objets imaginaires simplement à partir d’invites textuelles. D’autres concurrents comme Midjourney v6(26) et Stable diffusion XL(27) ont également été créés et mis à disposition de la communauté des outils digitaux similaires.

5.2 Les nouvelles applications possibles du NLP
De nouvelles applications apparaissent pour analyser des documents de type pdf. L’outil chatpdf (28) permet par exemple de télécharger un fichier pdf et de chatter avec le document. Cet outil est utilisé par exemple pour parcourir des documents scientifiques, des articles académiques et des livres pour obtenir les informations de manière rapide. Un autre outil assez similaire mais qui peut être lancé en local sur son ordinateur est PDFgear.
Il existe également des outils qui facilitent la recherche bibliographique. Parmi ces outils, nous retrouvons :
- Consensus(30) : une IA utilisée pour analyser les recherches évaluées par les pairs et extraire les principales conclusions de chacune d’entre elles.
- Scite(31) : il s’agit d’une IA qui permet aux utilisateurs de trouver les bonnes sources pour la rédaction d’articles scientifiques.
- Elicit (32) : c’est un outil qui est capable de localiser des articles pertinents et extraire des informations sans que la correspondance dans la requête soit réalisée avec des mots clés spécifiques. Cette IA peut aider à réaliser différents exercices d’exploration, notamment la conceptualisation, la synthèse et la mise en ordre du texte, ainsi que la synthèse des questions centrales pour la réalisation d’un rapport.
ResearchRabbit(33) : appelé par ses fondateurs “le Spotify de la recherche”, Research Rabbit permet d’ajouter des articles académiques à des “collections”. Ces collections permettent au logiciel de connaître les centres d’intérêt de l’utilisateur, ce qui donne lieu à de nouvelles recommandations pertinentes. ResearchRabbit permet également de visualiser le réseau d’articles des auteurs et des coauteurs sous forme de graphiques, afin que les utilisateurs puissent suivre le travail d’un seul sujet ou d’un seul auteur et se plonger plus profondément dans leur recherche.
- Scholarcy (34) ou PaperDigest (35) : ce sont des outils similaires qui résument les articles académiques et mettent en évidence les parties les plus importantes pour le lecteur. Ils permettent également de déterminer rapidement et facilement si un article est pertinent ou non. De plus, de nouvelles applications émergent comme les multi agents : il s’agit d’un ensemble d’agents autonomes interagissant entre eux pour atteindre des objectifs spécifiques. Chaque agent dans un système multi-agent est une entité autonome dotée de sa propre capacité de perception, de prise de décision et d’action.
Il existe à l’heure actuelle plusieurs IA de ce type dont :
- Autogen de Microsoft(36) : c’est une IA qui simplifie l’orchestration, l’optimisation et l’automatisation des flux de travail des LLM. Il offre des agents personnalisables et conversationnels qui exploitent les capacités les plus fortes des LLM et les plus avancées, comme GPT-4, tout en répondant à leurs limites en s’intégrant aux humains et aux outils et en ayant des conversations entre plusieurs agents via un chat automatisé.
- Mixtral (sparse mixture-of-expert)(37) : il s’agit d’un modèle basé uniquement sur la partie décodeur où à chaque couche, pour chaque token, un routeur choisit deux des huit groupes de paramètres disponibles (nommés les “experts”) afin de procéder à l’analyse du token et de combiner les résultats. Cette technique permet de réduire le nombre de paramètres d’un modèle tout en contrôlant le coût et la latence. En effet, ce type de modèle n’utilise qu’une fraction du total des paramètres définis par token. Par exemple, Mixtral a 46.7 milliards de paramètres totaux et n’utilise que 12.9 milliards de paramètres par token. Aussi, des modèles de type multimodal apparaissent. Il s’agit par exemple de GPT-4 et Gemini Pro. Ce sont des IA qui sont capables de comprendre, traiter et intégrer plusieurs types de données ou signaux d’entrée (texte, audio, image, vidéo, code informatique).
Parmi les cas d’usage, il y a par exemple le :
- “text to image” : à partir d’un texte, l’IA est capable de générer une image
- “text to music” : à partir d’un texte, l’IA est capable de générer de la musique
- “image to text” : à partir d’une image, l’IA donne une description des éléments qui y sont représentés.
Enfin, des modèles NLP sont développés pour des domaines spécifiques (juridique, règlementaire, médicale, scientifique, etc). Il existe des sites internet qui répertorient l’ensemble de ces variants de modèles comme HuggingFace(38) ou très récemment GPTStore(39). Pour finir, des entreprises comme Meta, souhaitent développer des IA génératives fiables et responsables (Purple Llama)(40). Ces IA sont testées par des équipes afin de s’assurer qu’elles ne produisent pas par exemple du texte à caractère haineux ou non éthique.
6. Conclusion
Cet article met en lumière un domaine fascinant de l’intelligence artificielle : le traitement du langage naturel (NLP). Nous plongeons dans l’histoire du NLP, de ses débuts dans les années 50 jusqu’à son état actuel, en suivant l’évolution constante des concepts et des technologies qui ont façonné les modèles actuels les plus sophistiqués. Tout au long de cette évolution, une panoplie de techniques de représentation et d’analyse textuelle ont été méticuleusement développées.
Aujourd’hui, le NLP imprègne divers secteurs avec des applications aussi variées que l’analyse et la synthèse de texte, la traduction, la recherche d’informations dans les documents, la classification, et même la génération de contenu. Cette ascension fulgurante trouve son élan dans l’évolution parallèle des outils matériels dédiés à l’apprentissage des modèles en exploitant les nouvelles technologies.
Les futurs développements se profilent vers des systèmes multimodaux qui ne se limitent pas au texte, mais englobent également la génération d’images, de sons et de vidéos. Enfin, les toutes dernières avancées se concentrent sur des modèles plus économes en ressources et sans compromettre les performances. Une ère passionnante s’ouvre dans le domaine du NLP, avec des horizons toujours plus vastes et des possibilités innovantes à explorer.
Partager l’article




References
- S. Vajjala, B. Majumder, A. Gupta & H. Surana. « Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems », 2020, Oreilly & Associates Inc, ISBN-10 : 1492054054.
- « A complete guide to Natural Language Processing », DeepLearning.AI, https://www.deeplearning.ai/resources/ natural-language-processing/
- A. M. Turing, « Computing Machinery and Intelligence », 1950, Mind 49: 433-460.
- Jacob Eisenstein, « Introduction to natural language processing », 2019, Adaptive Computation and Machine Learning series, ISBN : 9780262042840.
- « A brief history of NLP », World Wide Technology, https://www.wwt.com/blog/a-brief-history-of-nlp
- A. Grechanyuk, « A short explanation of the history of the natural language models », 2023, https://www.linkedin.com/ pulse/short-explanation-history-natural-language-models-anton-grechanyuk/
- R. Brachman, H. Levesque, « Readings in Knowledge Representation », 1985, Los Altos, Calif. : M. Kaufmann Publishers
- Y. LeCun, Y. Bengio & G. Hinton, « Deep learning », Nature, 2015, 521, 436–444
- K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk & Y. Bengio, « Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation », 2014, https://arxiv.org/abs/1406.1078
- Y Xiao, K Cho, « Efficient Character-level Document Classification by Combining Convolution and Recurrent Layers », 2016, https://arxiv.org/abs/1602.00367
- A. Sperduti & A. Starita, « Supervised neural networks for the classification of structures », 1997, IEEE Transactions on Neural Networks, 8, 714-735, doi: 10.1109/72.572108
- A. Kaparthy, « The Unreasonable Effectiveness of Recurrent Neural Networks », 2015, https://karpathy.github. io/2015/05/21/rnn-effectiveness/
- D. Bahdanau, K. Cho, Y. Bengio, « Neural Machine Translation by Jointly Learning to Align and Translate », 2014, https:// arxiv.org/abs/1409.0473
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, « Attention Is All You Need », 2017, https://arxiv.org/abs/1706.03762
- J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, « BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding », 2018, https://arxiv.org/abs/1810.04805
- I. Sharaf, « Introduction to Natural Language Processing (NLP) », 2019, https://towardsdatascience.com/introduction- to-natural-language-processing-nlp-323cc007df3d
- K. Spärck Jones, « A statistical interpretation of term specificity and its application in retrieval », 1972, Journal of Documentation, 28, 11-21
- T. Joachims, « Text categorization with Support Vector Machines: Learning with many relevant features ». In: Nédellec, C., Rouveirol, C. (eds) Machine Learning: ECML-98. ECML 1998. Lecture Notes in Computer Science, 1998, 1398, 137-142
- J. Firth, « A Synopsis of Linguistic Theory, 1930-55 », 1957, Linguistics
- T. Mikolov, K. Chen, G. Corrado & J. Dean, « Efficient Estimation of Word Representations in Vector Space », 2013, https://arxiv.org/ abs/1301.3781
- J. Pennington, R. Socher, C. D. Manning, « GloVe: Global Vectors for Word Representation », https://nlp.stanford.edu/pubs/glove.pdf 22.
- A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou & T. Mikolov, « FastText.zip: Compressing text classification models », 2016, https://arxiv.org/abs/1612.03651
- M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee & L. Zettlemoyer, « Deep contextualized word représentations », 2018, https://arxiv.org/abs/1802.05365
- GPT-4, https://openai.com/chatgpt
- Google Gemini, https://openai.com/chatgpt
- Midjourney v6, https://mid-journey.ai/midjourney-v6-release/
- StableDiffusion XL, https://stablediffusionweb.com/StableDiffusionXL
- Chatpdf, https://www.chatpdf.com/
- PDFGear, https://www.pdfgear.com/fr/
- Consensus, https://consensus.app/
- Scite, https://scite.ai/
- Elicit, https://elicit.com/
- ResearchRabbit, https://www.researchrabbit.ai/
- Scholarcy, https://www.scholarcy.com/
- PaperDigest, https://www.paperdigest.org/
- « AutoGen: Enabling next-generation large language model applications », 2023, https://www.microsoft.com/en-us/research/blog/autogen-enabling-next-generation-large-language-model-applications/
- Mixtral, https://www.microsoft.com/en-us/research/blog/autogen-enabling-next-generation-large-language-model- applications/
- HuggingFace, https://huggingface.co/
- GPTStore, https://gptstore.ai/plugins
- Purple Llama, https://ai.meta.com/llama/purple-llama/
