


Sommaire
- Continued Process Verification stratégie de visualisation des données dans le cadre de la CPV
- Démarche de déploiement de la Vérification Continue des Procédés & gains associés, sur un site de production pharmaceutique
- Intervalles statistiques de tolérance : Quelles alternatives en cas de non-normalité ?
- Comment construire une stratégie d’échantillonnage adaptée en fonction des risques
- Sécurisation des approvisionnements : stratégie & outils pour maitriser les risques de rupture
- Advanced Data Analysis as an enabler to near real-time Contamination Control Strategy Evaluation
- L’IA diagnostic. L’analyse d’images
Continued Process Verification, stratégie de visualisation des données dans le cadre de la CPV.
Le GIC A3P CPV a repris du service pour faire évoluer le guide Volume 6 sur la Continued Process Verification, notamment pour exemplifier les différentes notions et y intégrer plusieurs arbres décisionnels. Une nouvelle version du guide sera bientôt disponible. Au travers des deux articles suivants, le GIC souhaite illustrer deux aspects de la CPV.

L’Ongoing Process Verification (OPV – EU)[1] ou la Continued Process Verification (CPV – US)[2] est un système qualité de surveillance de l’état validé du procédé tout au long de son cycle de vie. La CPV est construite à partir des études de caractérisation et des éléments de la validation initiale afin de garantir une acquisition pertinente de connaissances sur le produit et le procédé. Elle est complémentaire et contributive pour les systèmes qualité existants (e.g. Change Management, APR/PQR, …). A terme, la CPV a pour finalité d’accélérer le processus de libération des lots en facilitant les investigations.
Dans le prolongement de la Process Validation (Process Performance Qualification- US[2]), la CPV se doit d’évaluer la maîtrise du procédé sur un nombre de lots plus élevé que celui mis en œuvre à l’initial. Le programme de CPV doit donc considérer les conclusions de la Validation du procédé pour l’établissement des indicateurs à suivre, de la fréquence et de la méthodologie d’analyse des données.
Dans le programme CPV, il est requis d’établir la méthodologie permettant de mesurer la performance du procédé et ses variabilités. Il s’agit de démontrer la maîtrise de la transformation de la matière tout au long du procédé d’obtention du produit. Pour cela, la stratégie de CPV doit fixer le choix des éléments à suivre parmi les Critical Process Parameters (à défaut les Critical Equipment Parameters), les contrôles en cours de procédé critiques (les Critical In-Process Controls), les Critical Material Attributes, les Critical Quality Attributes, considérés comme tout indicateur contribuant directement à la Qualité du produit.
La sélection des indicateurs et la manière de les analyser conditionnent l’acquisition progressive de la connaissance. L’arbre décisionnel en Figure 1 explique le processus de mise en place d’une stratégie de visualisation des données.
Dans la logique de sélection des bonnes valeurs à suivre en CPV, il s’agit d’évaluer si la valeur des Critical Process Parameters, des Critical In-Process Controls, des Critical Material Attributes ou des Critical Quality Attributes est une valeur mesurable et/ou quantifiable. Si nous avons à faire à des données quantitatives, nous disposons alors de variables pouvant se traduire par des valeurs numériques ; pour chaque individu, la valeur d’une variable représente une quantité. Avec des séries de valeurs quantitatives, il est possible de s’appuyer sur des statistiques descriptives, fournissant ainsi un récapitulatif concis des données sous forme numérique ou graphique.
Si la valeur des données suivies est de nature qualitative, il s’agit de faire une analyse spécifique de ces données en fonction de leur catégorie (i.e. nominale, ordinale, binaire [3]). Dans le contexte de la CPV, les valeurs qualitatives peuvent être des informations provenant des évènements qualité tels que les OOS/OOT, déviations, réclamations en lien avec les valeurs critiques. Ce sont des indicateurs complémentaires qui doivent être intégrés au programme de CPV au fil de l’apparition d’occurrences relatives à ces évènements. Il peut également s’agir des sources d’une matière première ou de plusieurs équipements différents utilisés tour à tour sur un même procédé/produit, nécessitant une comparaison de performance.
Le diagramme circulaire, communément appelé “camembert” (figure 2), permet de représenter des séries dont le caractère est qualitatif. Les parts du diagramme sont des surfaces qui sont proportionnelles au nombre de chaque modalité.

Les données du diagramme circulaire peuvent également être représentées sous formes de colonnes empilées. Cette dernière représentation graphique a un certain intérêt pour mieux visualiser des évolutions entre deux études des données qualitatives (Figure 3).
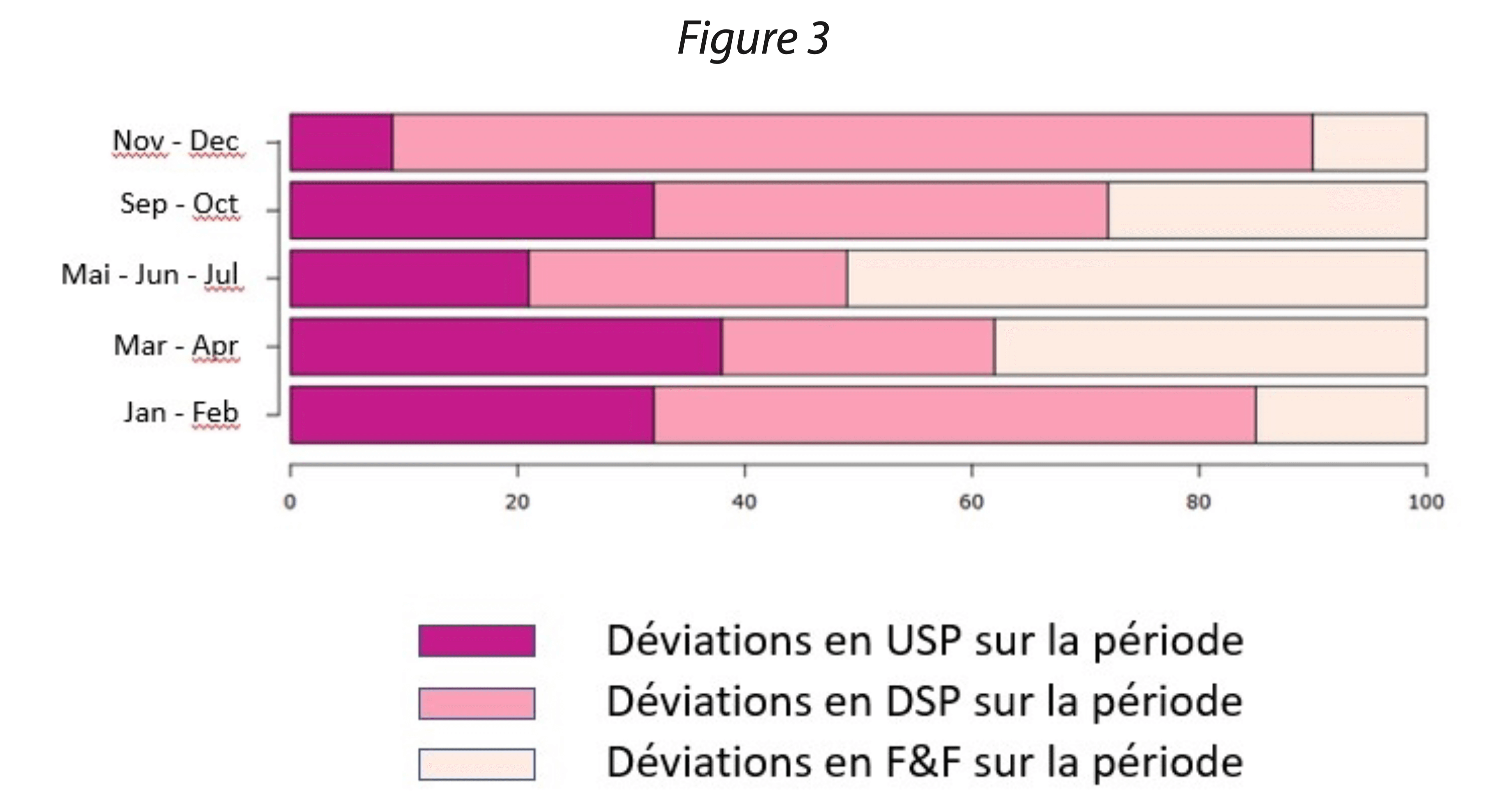
Pour cibler l’effort des statistiques descriptives, il est primordial de vérifier si les données quantitatives sont alarmées ou pas. Dans le cas où les données proviennent d’un système doté des moyens d’avertir d’une potentielle dérive ou d’un dépassement des seuils autorisés, le suivi des dites données n’est pas requis. Le maintien des critères tout au long du cycle de vie est alors garanti par le système. Pour utiliser un dispositif d’avertissement, il est requis de le qualifier, d’éprouver sa robustesse, sa fiabilité. Des valeurs qui sont alarmées en cas de sortie des spécifications sont soumises au processus de gestion des déviations, déviations qui font alors partie des données qualitatives évoquées précédemment.
La première étape des statistiques descriptives consiste à mettre sous forme graphique les séries de données.
En présence d’une multitude de données, souvent sous forme de liste ou de tableau, nous avons beaucoup de mal à en dégager une tendance et/ou apprécier une dispersion des données. Avec une représentation visuelle, tout s’éclaire ; un graphique est une représentation de données statistiques mettant en lumière le comportement de la série étudiée. Et s’il existe plusieurs types de données, il y a aussi différents types de graphiques pour chercher la meilleure visualisation de données possible.
Il faut savoir qu’un panel de graphiques différents sont à disposition pour illustrer la distribution des valeurs. Ceux-ci ne sont pas interchangeables mais complémentaires.
Dans un exercice de CPV, les graphiques “stars” sont l’histogramme, les cartes de contrôle et la boîte à moustaches.[4]
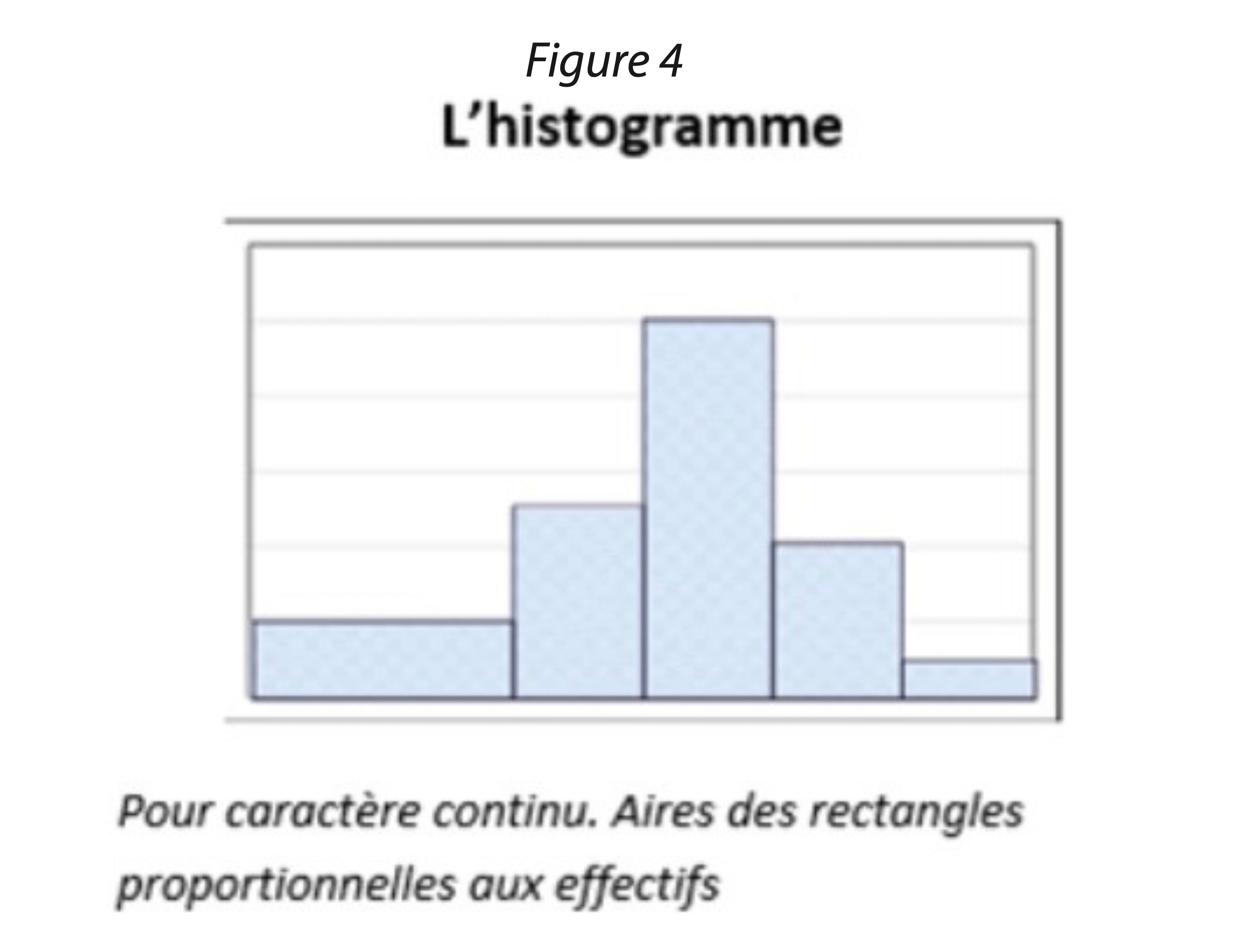
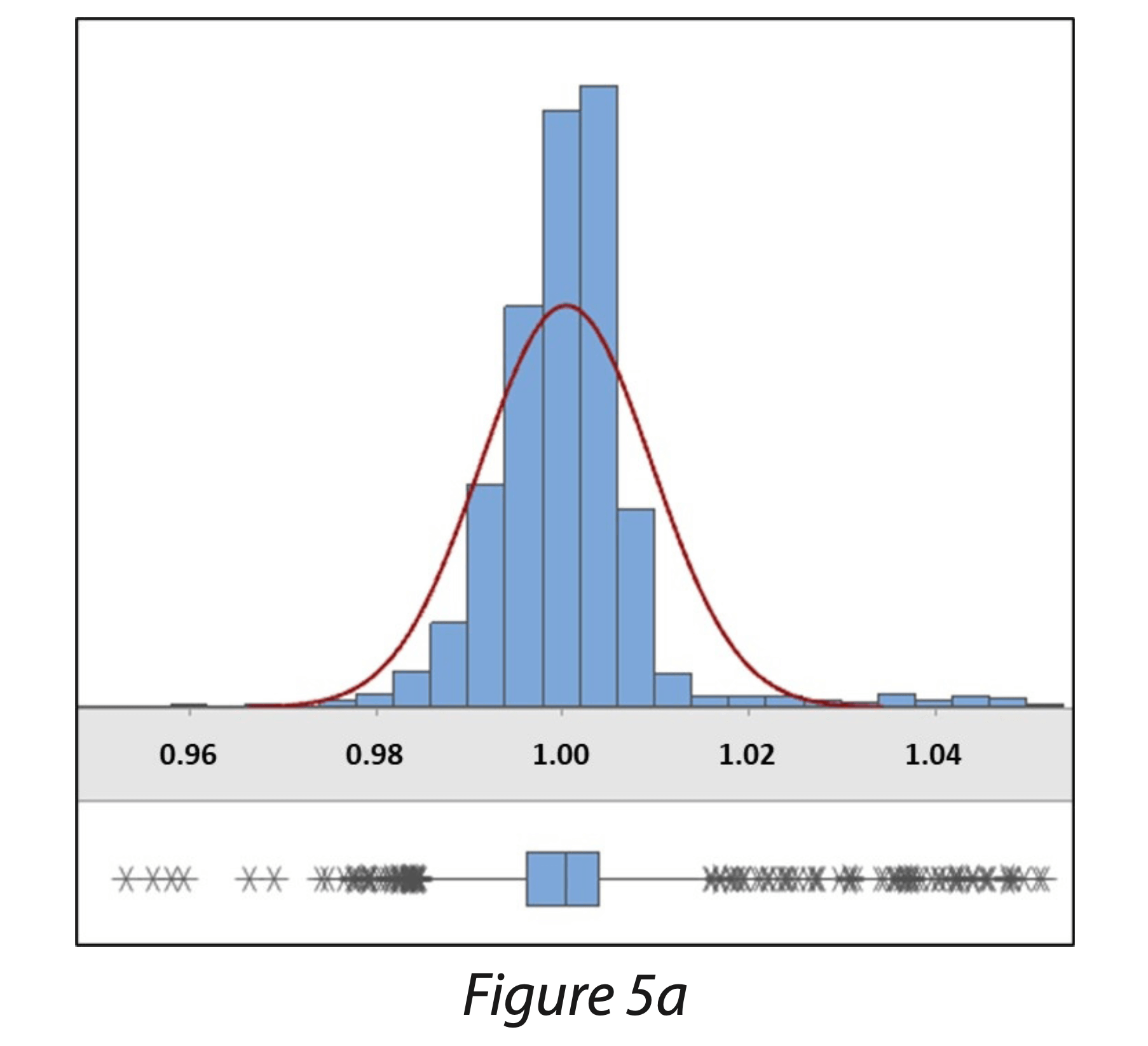
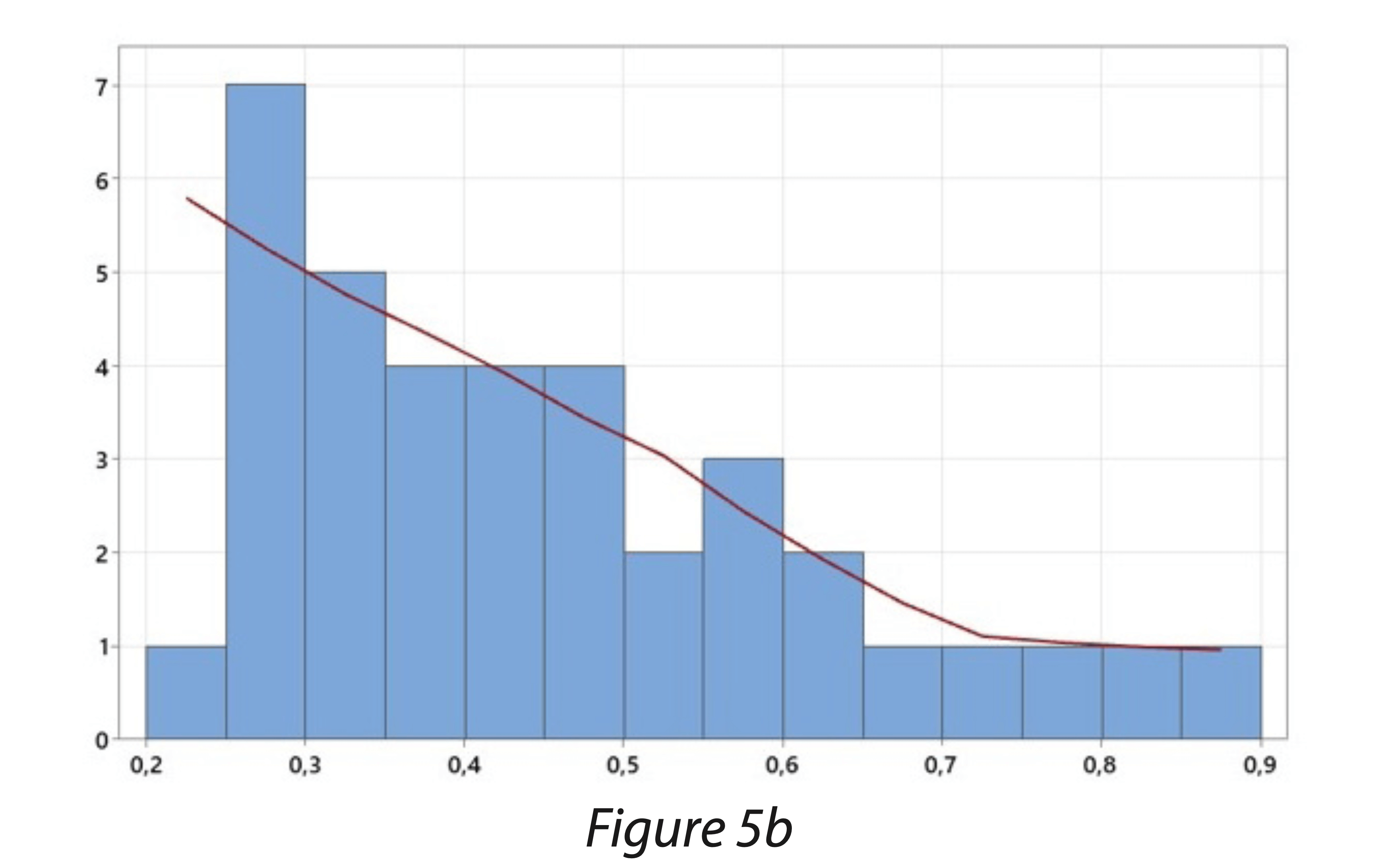
L’histogramme permet de visualiser une série dont le caractère est quantitatif et continu. Il est formé de rectangles mitoyens dont les aires sont proportionnelles aux effectifs. On le construit à partir de classes de valeurs. L’utilisation de logiciels statistiques permettent la construction automatique de tels graphiques.
Les données représentées sous forme d’histogramme sont généralement issues d’une série de valeurs très nombreuses permettant ainsi de dégager une forme de distribution prépondérante. De cette manière, il est possible d’apprécier si nous sommes face à une distribution aléatoire des données issues du procédé (se rapprochant d’une distribution normale) ou à une forme de distribution ayant une causalité du comportement.
Les figures 5 sont des exemples de volumes de remplissage de seringues (Figure 5a) et de taux d’humidité résiduelle dans des lyophilisats (Figure 5b).
Les cartes de contrôle sont des graphiques qui tracent des données quantitatives continues/discrètes de procédé en séquences ordonnées chronologiquement. La plupart des cartes de contrôle incluent une ligne centrale, une limite de contrôle supérieure et une limite de contrôle inférieure. La ligne centrale représente la moyenne du procédé μ. Les limites de contrôle représentent la variation du procédé. Les cartes de contrôle peuvent également inclure les limites de spécification inférieure et supérieure.
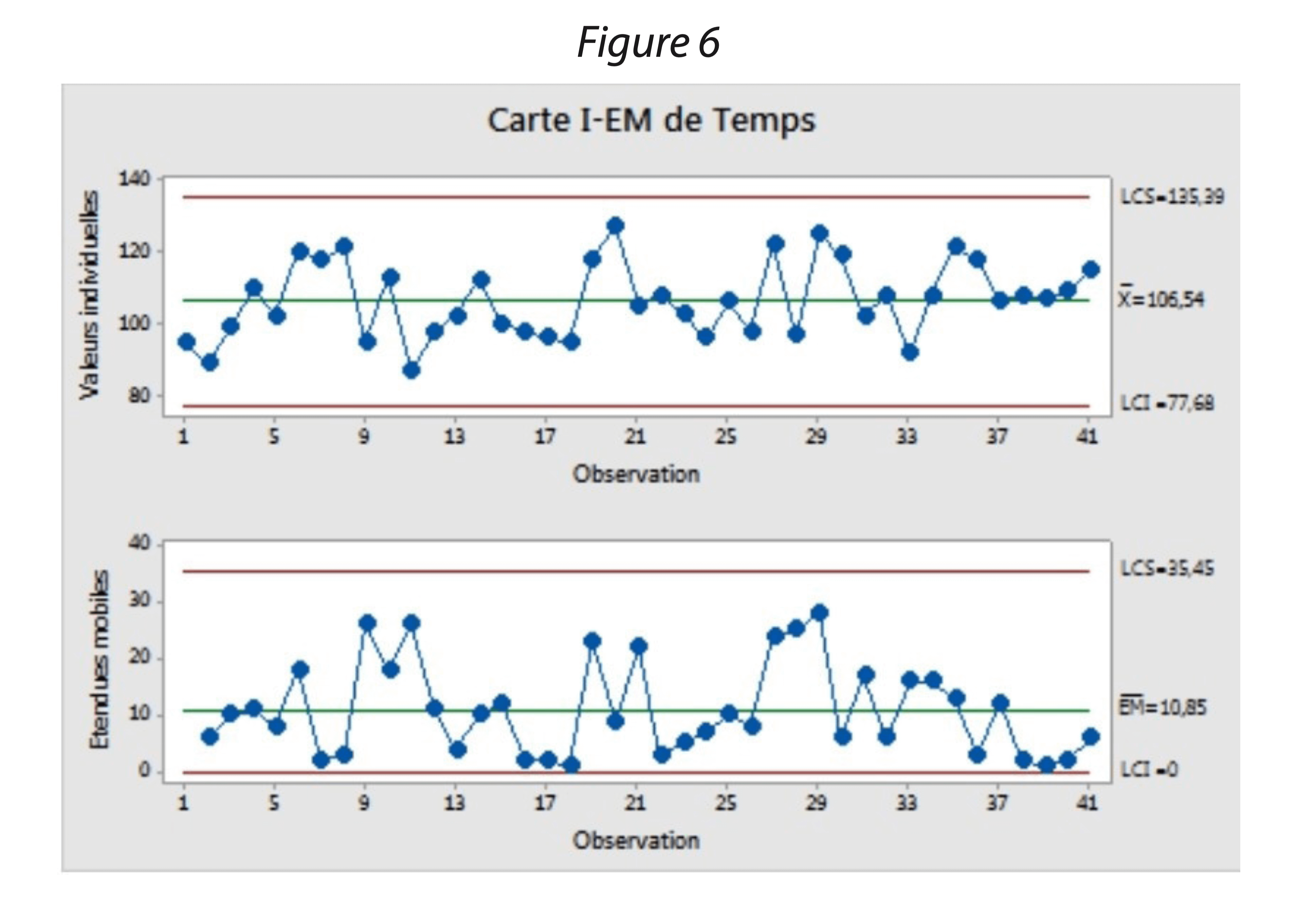
En règle générale, une carte de contrôle montre l’évolution lot à lot d’une caractéristique des lots produits. Pour chaque lot, plusieurs cartes de contrôle sont établies pour apprécier la robustesse d’un procédé donné au travers de la constance de la qualité du produit. Comme recommandé dans le Guidance for Industry de la Process Validation de 2011[2], la collecte et l’évaluation de données sur les performances du procédé permettront de détecter la variabilité indésirable du procédé dans le cadre du processus CPV. La carte de contrôle est le moyen incontournable pour représenter et décrire la variabilité potentielle inter-lot.
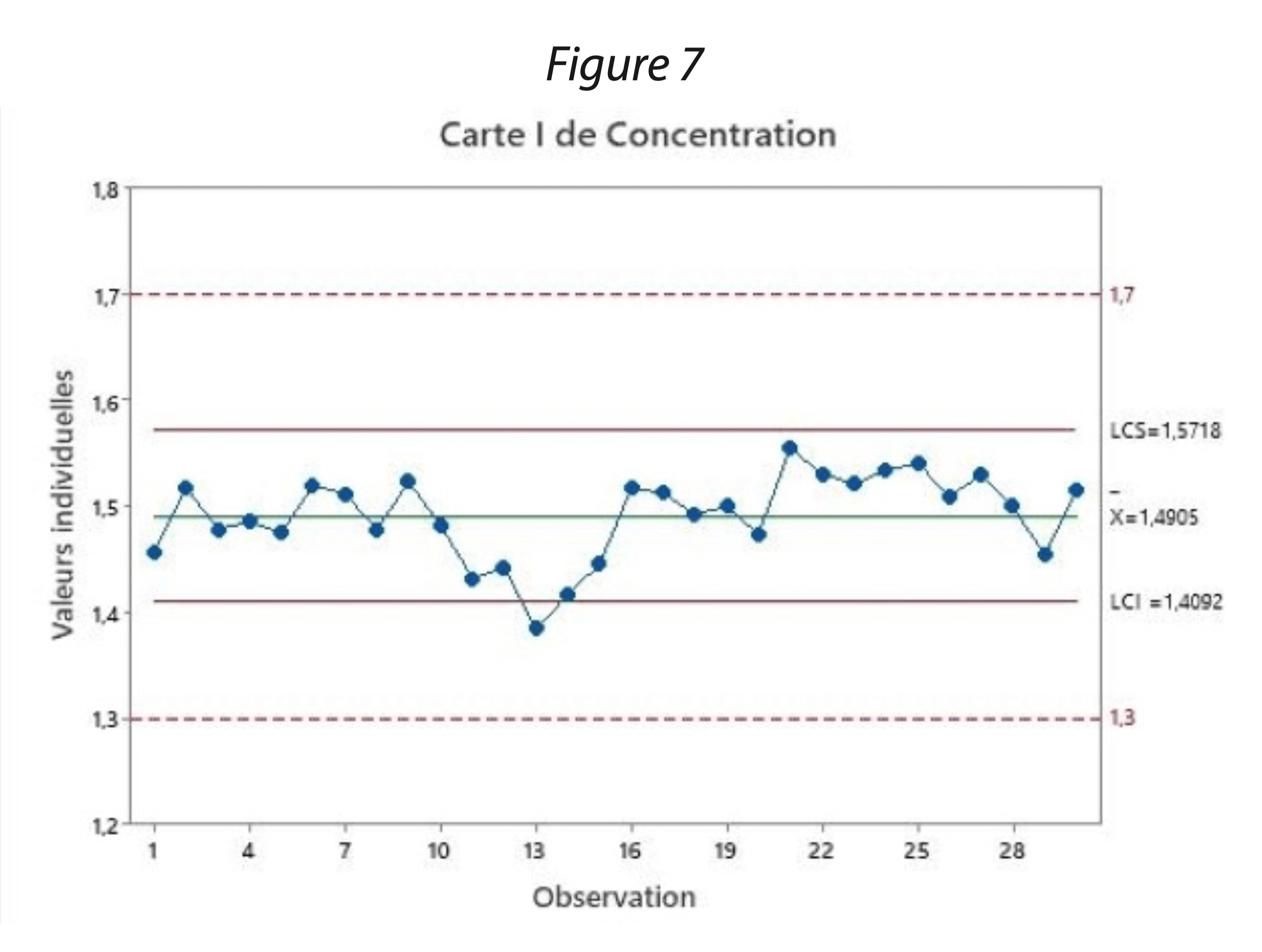
La figure 7 représente le relevé de concentration d’un traceur une cuve de formulation pour une cible de 1,5 mg/L. La carte de contrôle indique la moyenne obtenue sur les 30 premiers lots de production. A partir de la moyenne ainsi que l’écart-type les limites de contrôle inférieure (LCI) et supérieure (LCS) ont pu être calculées.
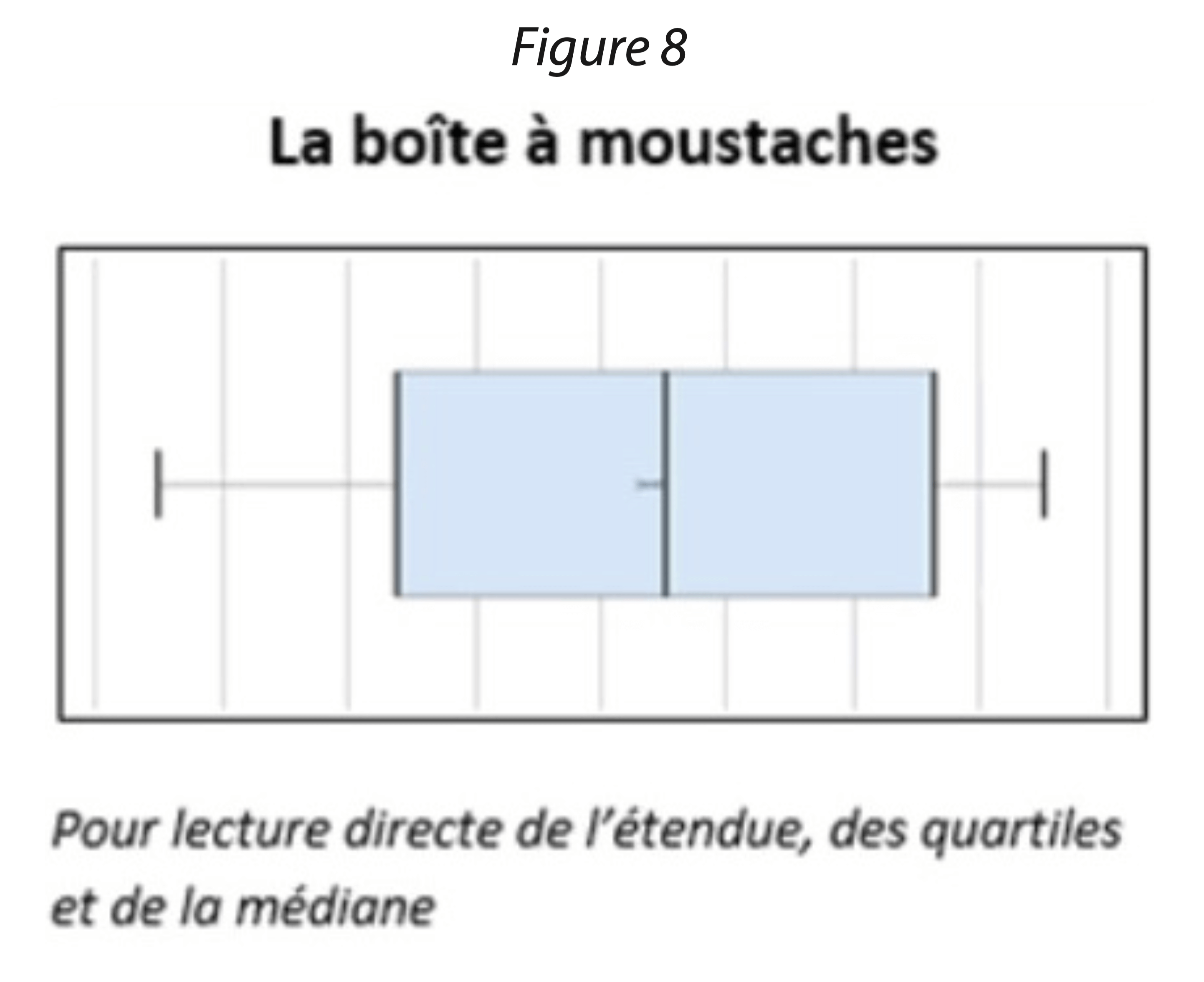
La boîte à moustaches (figure 8) présente une synthèse de la dispersion d’une série statistique. Sa représentation et la symbolique utilisée en font un graphisme délicat à interpréter. L’intérêt de ce type de graphe est surtout de comparer entre elles plusieurs populations (ou échantillons) dans un contexte de statistiques inférentielles[5].
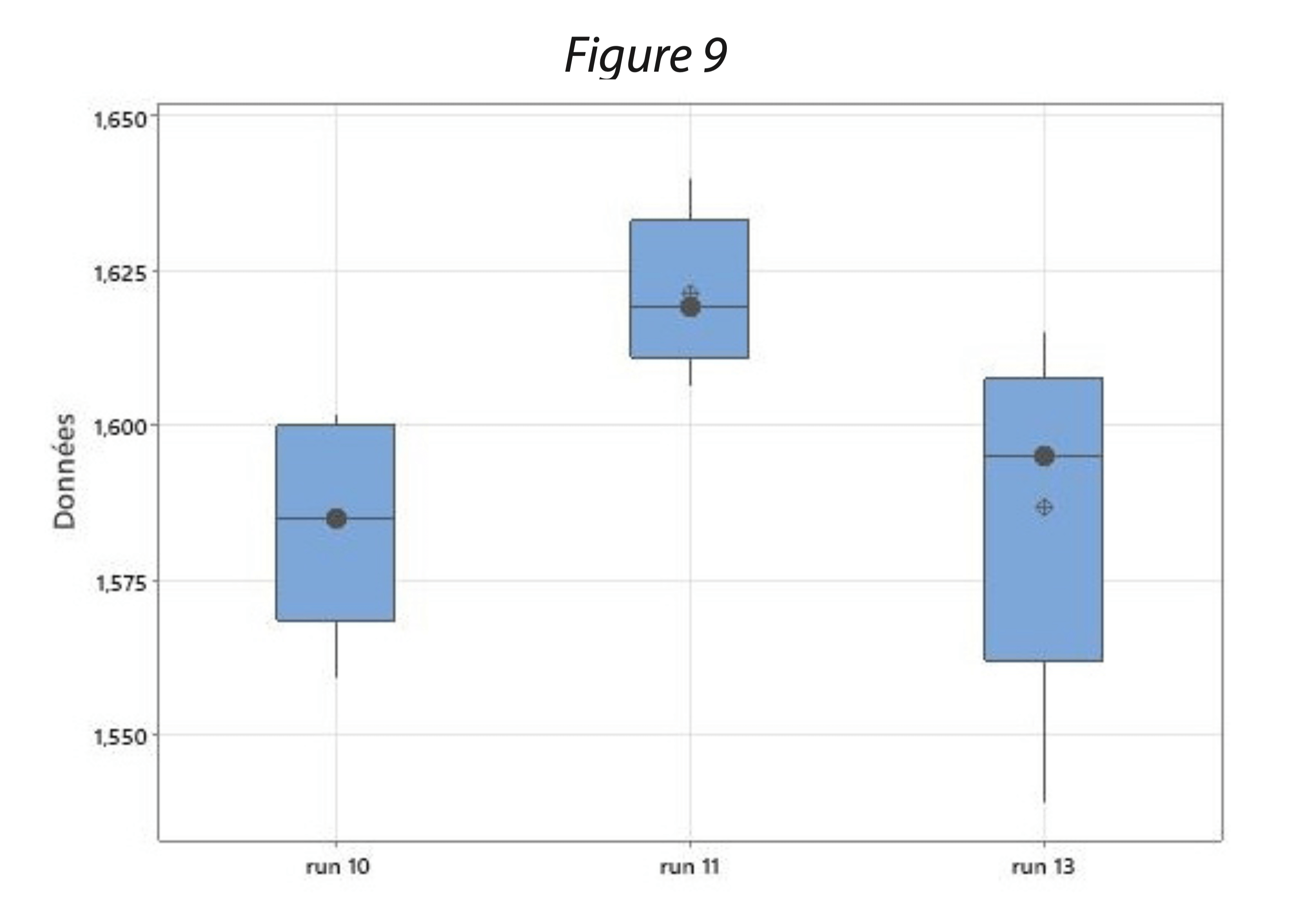
La figure 9 représente le relevé de concentration d’un traceur dans des produits finis et met en évidence une dispersion de cette concentration sur 3 runs de production.
Cette différence dans l’utilisation des indicateurs descriptifs est rarement prise en compte par les personnes en charge des exercices de CPV. Souvent la moyenne et l’écart-type restent les indicateurs des analyses descriptives sans que la normalité soit prouvée.
Est-ce abusif ? Est-ce-que cela pourrait avoir un impact sur les conclusions obtenues ? La littérature souligne que certains tests sont robustes à l’hypothèse de normalité et d’autres non [6].
En règle générale, les tests d’hypothèse robustes à la normalité sont des tests basés sur les moyennes. Il est admis dans un cas de non- normalité, d’approcher par une loi normale avec les outils adaptés (forme de la courbe, coefficient d’asymétrie et d’aplatissement de la courbe, droite de Henry, présence ou non de valeurs aberrantes…).
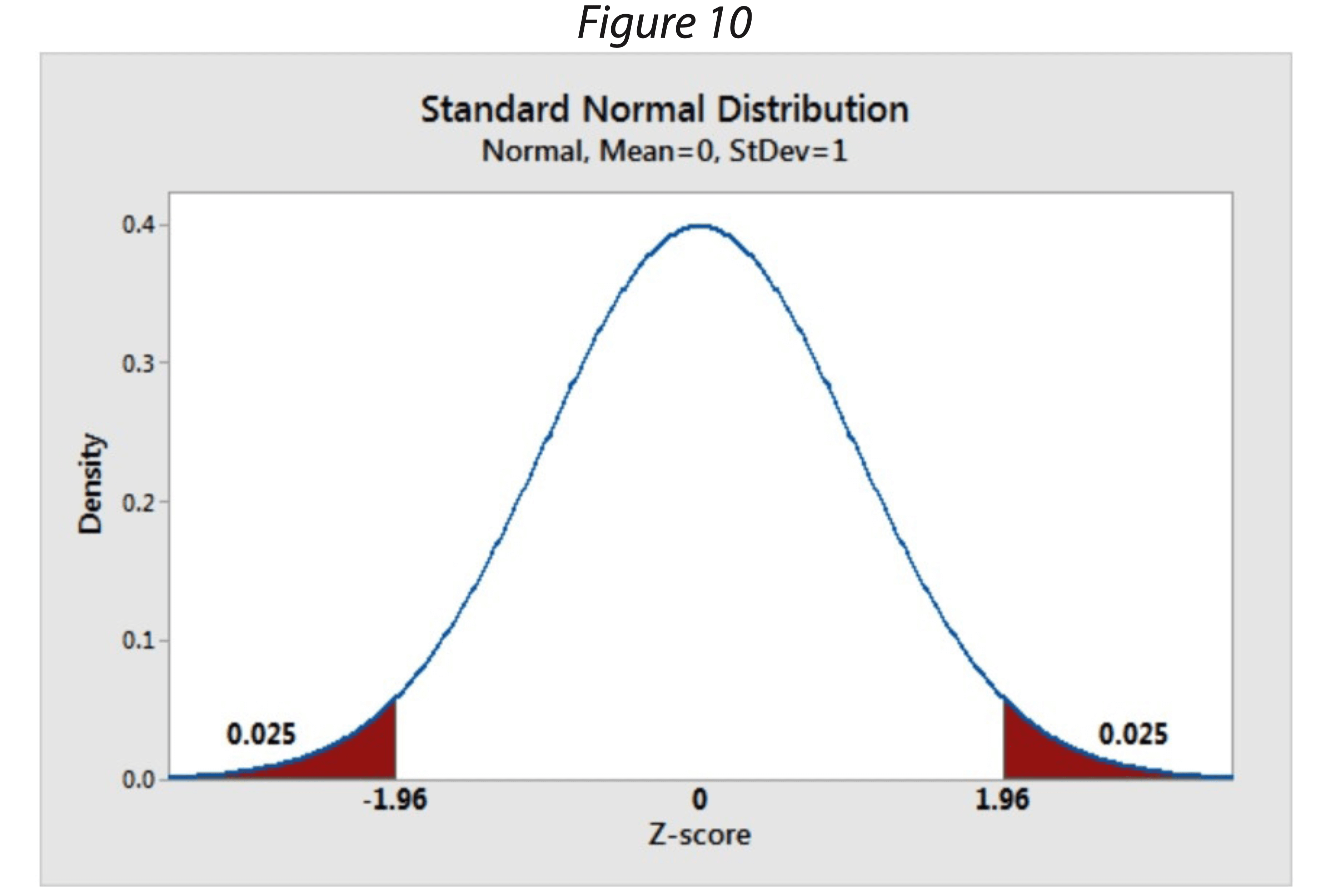
A noter que pour les tests basés sur des valeurs individuelles ou sur l’analyse des queues de distribution (figure 10 représentant les queues de chaque côté de la distribution), la normalité devient vraiment critique. Ce qui veut dire, que l’analyse de la capabilité pour déterminer les Cpk et Ppk ou le calcul des Intervalles de tolérance sont sensibles à la normalité des distributions car les calculs réalisés pour ces analyses sont basés sur l’écart-type. La détermination de ces indices est alors à faire selon des équations spécifiques.
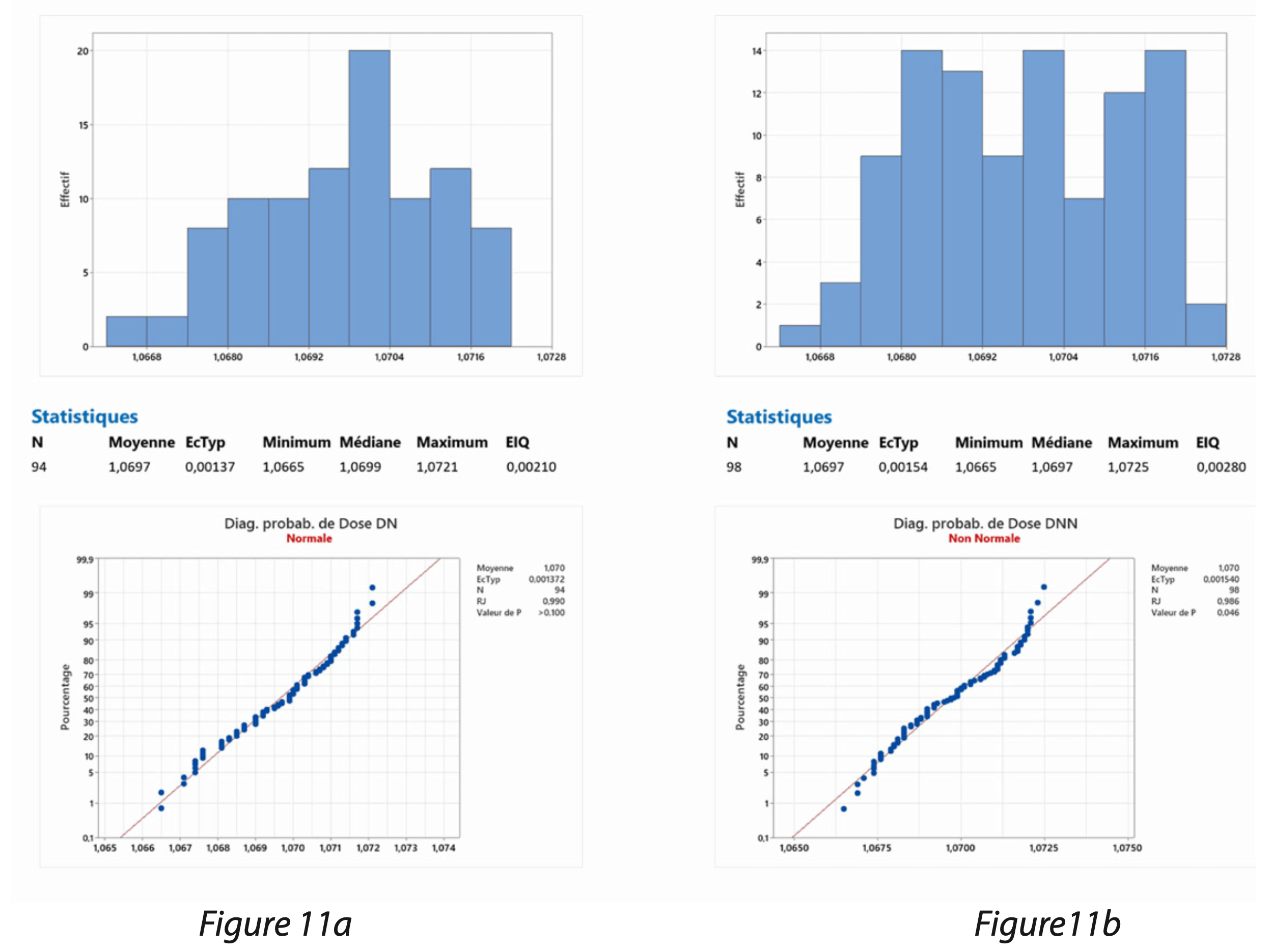
Les figures 11 sont des exemples de distribution normale (figure 11a) et de distribution non normale (figure 11b). Il s’agit de valeurs de volume de remplissage dans deux configurations de réglage des deux pompes. Les volumes suivent, dans un cas, une loi normale en raison d’une superposition des distributions des deux pompes et dans le second cas, les volumes sont issus de deux distributions non alignées en raison d’un décalage de réglage des pompes.
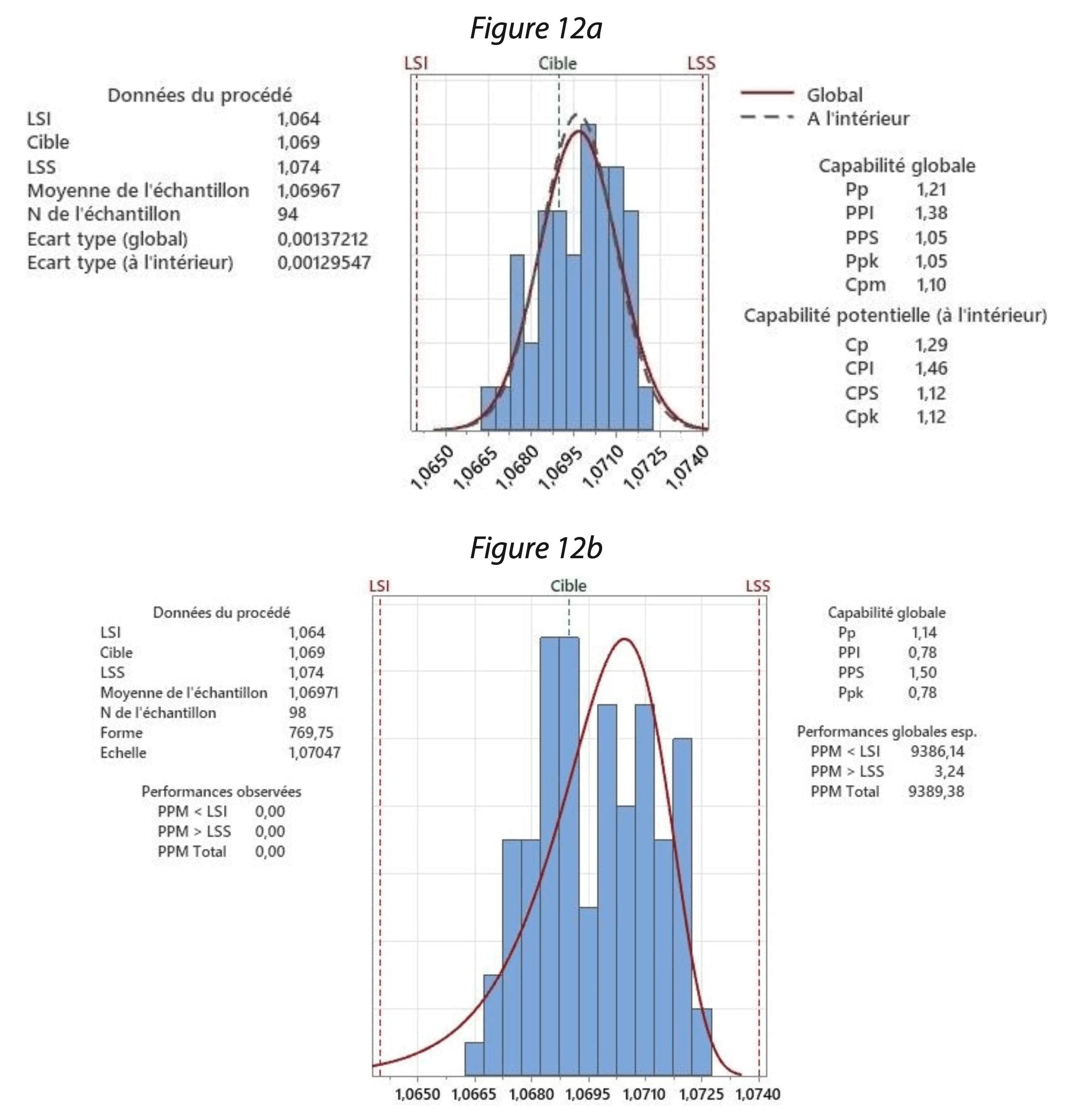
Une fois les statistiques descriptives attendues pour l’ensemble des indicateurs retenus pour le programme CPV sont mises en œuvre, l’étape suivante de l’arbre décisionnel de la figure 1 prévoit une analyse fine des cartes de contrôles et/ou un calcul de l’indice de capabilité en fonction de l’existence ou non d’une tolérance acceptable autour de la cible pour l’indicateur CPV.
Ainsi, dans le cas où des limites basses et hautes existent pour des valeurs suivies, il est possible de calculer un niveau de capabilité du procédé ou de la machine à maîtriser, par exemple, un Critical In- Process Control ou un Critical Quality Attribute.
En reprenant les exemples des figures 11a et 11b, des indices de capabilité peuvent être calculés suivant les formules adaptées respectivement à une distribution normale (Cpk et Ppk) ou à une distribution non normale (uniquement Ppk).
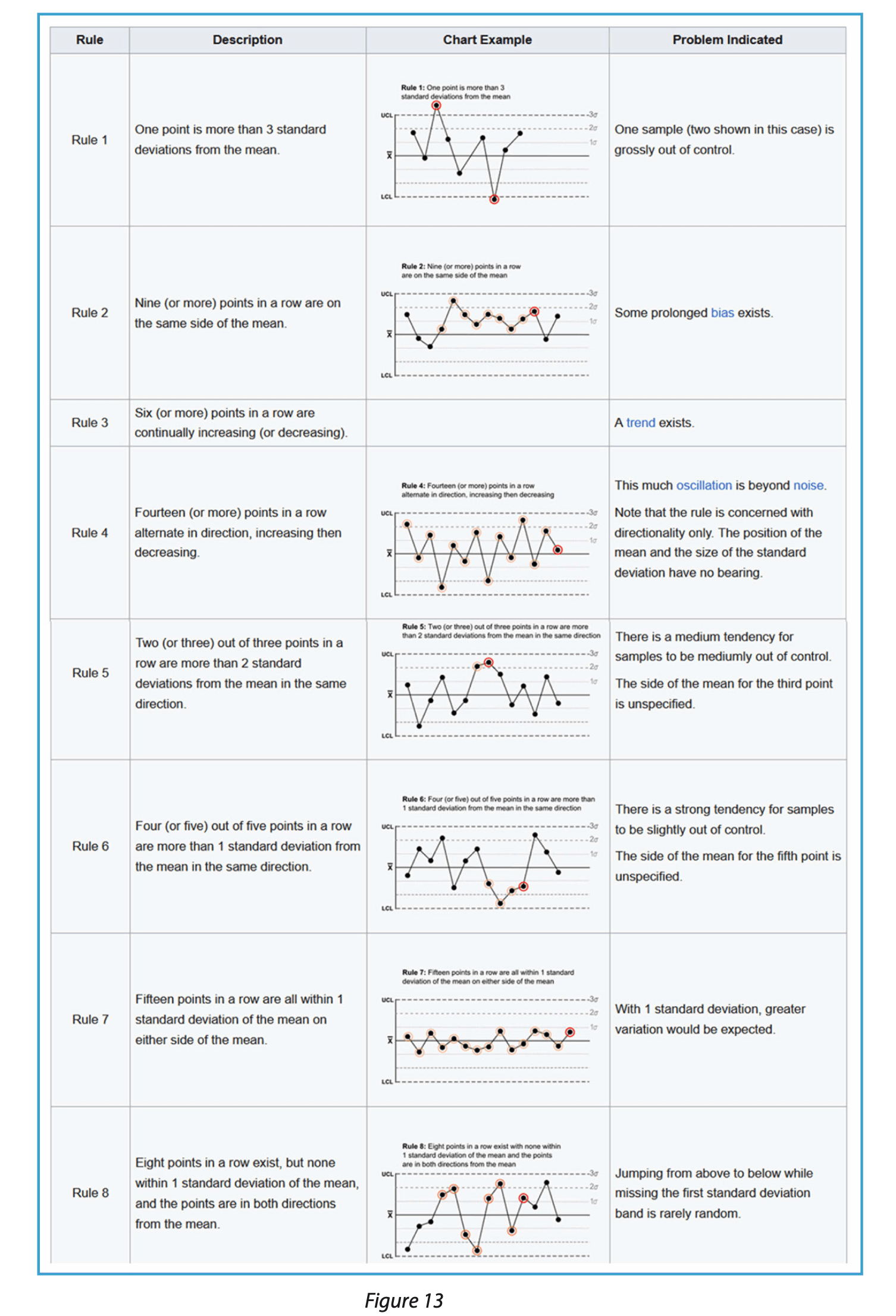
Dans le cas où aucune limite basse et haute n’est définie pour des valeurs suivies, l’arbre décisionnel recommande de faire des analyses fines sur les cartes de contrôle établies en appliquant les règles de Nelson. Bien que celles-ci ne sont pertinentes qu’avec des distributions suivant une loi normale, elles permettent de localiser d’éventuelles anomalies dans la succession des valeurs et donc dans la succession des lots de production.
Il est aisé de trouver la littérature détaillée sur les règles de Nelson qui sont au nombre de huit [8]. (voir figure 13 page suivante)
Les 3 premières règles doivent amener à réagir et à enquêter dans le cadre de la CPV car elles permettent d’apprécier si le procédé est maîtrisé au fil des productions. Quant aux autres règles, il s’agit d’alerter sur un comportement potentiellement non aléatoire du procédé. Le guide CPV détaille l’interprétation des règles dans le cadre du processus CPV.
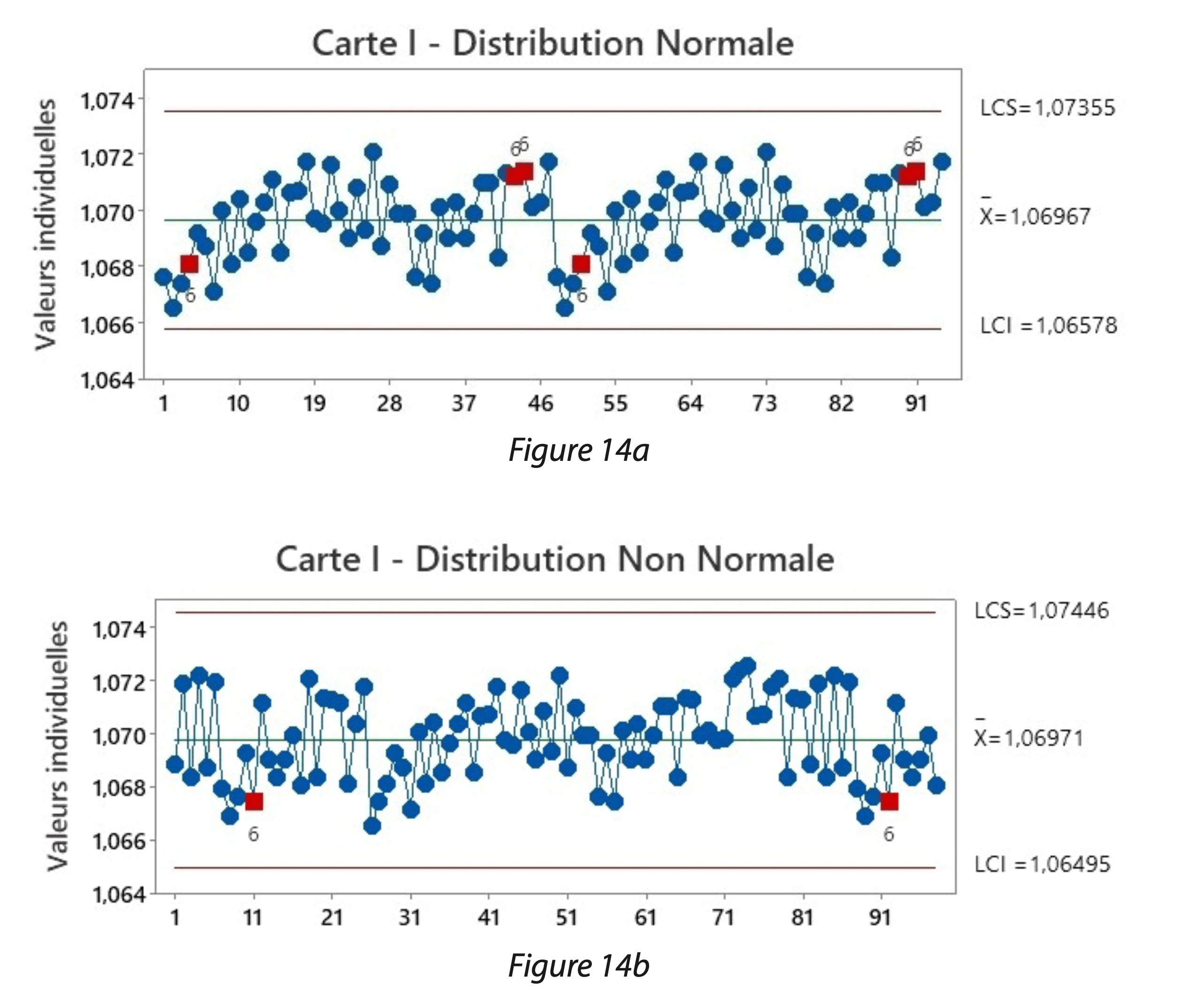
En reprenant toujours les données précédentes, les cartes de contrôles figures 14 mettent en évidence que certaines positions de données déclenchent la règle 6 à plusieurs reprises.
Y a-t-il un risque de décalage de la valeur centrale du procédé à différents moments sur la période utilisée ?
Au fil du monitoring, le maintien de l’état validé est jugé selon deux critères, la tenue des critères d’acceptation définie pour la CPV et l’absence de dérive significative.
Une dérive significative non justifiée par un évènement qualité débouchera la plupart du temps sur un ajustement du programme établi mais pourra dans certains cas, nécessiter des analyses ad hoc pour identifier des nouveaux modèles.
Dès lors que le procédé et ses variabilités sont sous CPV, plusieurs éléments du Pharmaceutical Quality System (PQS) s’en trouvent facilités. En effet, certaines données supportives entrant en ligne de compte pour, par exemple, établir les APR/PQR ou justifier les modifications, sont déjà compilées et analysées en continu par la CPV.
L’implémentation de la CPV absorbe donc une part de la charge de travail de ces processus qualité.
Partager l’article

Références
1. GMP Volume 4; Annex 15: Qualification and Validation – 2015
2. Process Validation: General Principles and Practices, January 2011
3. Statistiques de base – recherche bibliographique sur le web : https://fad.univ-lorraine.fr/pluginfile.php/23861/mod_resource/content/1/co/Nature_enristrement.html
4. Les graphiques statistiques – recherche bibliographique sur le web : http://www.jybaudot.fr/Stats/graphiques.html
5. Aide-mémoire Minitab – recherche bibliographique sur le web : https://support.minitab.com/fr-fr/minitab/20/help-and-how-to/statistics/basic-statistics/supporting-topics/basics/what-are-descriptive-and-inferential-statistics/
6. Que faire si mes données ne suivent pas une distribution normale ? – recherche bibliographique sur le web : https://blog.minitab.com/fr/que-faire-si-mes-donnees-ne-suivent-pas-une-distribution-normale
7. Should I Always Transform My Variables to Make Them Normal? / Dois-je toujours transformer mes variables pour les rendre normales ? – recherche bibliographique sur le web : https://data.library.virginia.edu/normality-assumption/
8. Nelson Rules – recherche bibliographique sur le web : https://en.wikipedia.org/wiki/Nelson_rules

GIC Continued Process Verification
