


Sommaire
- Continued Process Verification stratégie de visualisation des données dans le cadre de la CPV
- Démarche de déploiement de la Vérification Continue des Procédés & gains associés, sur un site de production pharmaceutique
- Intervalles statistiques de tolérance : Quelles alternatives en cas de non-normalité ?
- Comment construire une stratégie d’échantillonnage adaptée en fonction des risques
- Sécurisation des approvisionnements : stratégie & outils pour maitriser les risques de rupture
- Advanced Data Analysis as an enabler to near real-time Contamination Control Strategy Evaluation
- L’IA diagnostic. L’analyse d’images
Intervalles statistiques de tolérance : Quelles alternatives en cas de non-normalité ?
Différentes méthodes statistiques proposent des intervalles encadrant des données individuelles ; les méthodes les plus connues sont les cartes de contrôles – avec leurs célèbres ± 3 écart- types -, les intervalles de tolérances pour prédire un certain pourcentage de futures données avec une certaine probabilité, et les intervalles de prédiction pour prédire un nombre précis de valeurs avec une certaine probabilité.

Ces méthodes exigent la normalité de la distribution sous-jacente des données, car elles proposent des intervalles sous la forme “moyenne ± k x écart-type”, k étant un facteur variant selon la méthode retenue. Des approches non-paramétriques sont parfois proposées, se basant souvent sur les quantiles empiriques.
Après quelques rappels sur la normalité, cet article s’intéressera aux intervalles de tolérance (qui prédisent un certain pourcentage de futures données avec une certaine probabilité) et étudiera les alternatives non-paramétriques utilisables.
1. Rappel concernant la normalité
De nombreux tests statistiques permettent d’étudier la normalité d’une variable aléatoire continue. Le test de Shapiro-Wilk et celui de Kolmogorov-Smirnov sont les plus connus et les plus utilisés.
Le principe consiste à comparer la p-value du test à un seuil alpha choisi. Le seuil de 1% est régulièrement sélectionné car les méthodes sont souvent robustes à un léger écart à la normalité. Lorsque la p-value est inférieure à 1%, la normalité est rejetée. Dans le cas contraire, il n’y a pas de raison de la rejeter.
Un test de normalité fait sur un échantillon de petite taille est peu puissant : il rejette rarement l’hypothèse de normalité lorsque celle-ci n’est pas vérifiée. C’est pourquoi il est important que l’expert challenge la pertinence des calculs qu’il effectue.
A l’inverse, lorsqu’il y a beaucoup de données, le test statistique est puissant et rejette facilement la normalité. Dans ce cas, il est recommandé d’effectuer un graphique pour confirmer -ou non- le résultat du test.
Différents outils graphiques permettent de visualiser la distribution de données. Le QQ Plot ou droite de Henry permet de déterminer si les données s’écartent d’une loi normale. L’autre outil fréquemment utilisé pour visualiser la distribution est l’histogramme. La représentation de la loi de densité sous-jacente est alors ajoutée sous la forme d’une courbe, par exemple la courbe en cloche de la loi normale.
Il est possible d’estimer plus finement la densité de la variable aléatoire en utilisant un estimateur continue de la fonction de densité sous- jacente. Cet estimateur de la fonction de densité va définir une courbe qui s’ajuste au plus près de la densité de la variable aléatoire considérée : elle permet de mieux comprendre le jeu de données grâce à cette courbe lissée qui est plus visuelle que les barres de l’histogramme. L’estimateur non paramétrique de la fonction de densité est affiné en fonction de deux paramètres : le choix du noyau et la largeur de bande, qui ont des impacts directs et visibles sur l’ajustement.
L’utilisateur fait le choix d’un noyau et d’une largeur de bande dans son logiciel. Les simulations effectuées dans ce document utilisent un noyau gaussien et une estimation de la largeur de bande calculée par estimateur plug-in, qui sont les paramètres par défaut du logiciel SAS. Ce paramétrage est biaisé sur un échantillon fini car il surestime les résultats[1] ; il est néanmoins présenté dans ce document du fait de sa simplicité d’utilisation et de sa disponibilité dans beaucoup de logiciels. Des approches alternatives sont proposées à la fin de ce document.
La normalité pourra être jugée acceptable si l’histogramme montre une proximité entre la courbe d’ajustement de la loi normale et la courbe lissée de Kernel. Dans le cas d’intervalles statistiques, l’étude consiste à calculer une moyenne et un écart-type ; de petits écarts à la normalité ne vont pas modifier de façon majeure ces paramètres et il est possible d’accepter de légers écarts à la normalité.
Par exemple, sur le graphique ci-dessous, le test de Kolmogorov- Smirnov rejette l’hypothèse de normalité. Cependant, l’écart entre la courbe lissée de kernel (en bleu) et la courbe normale (en rouge) est faible. La moyenne et l’écart-type ayant permis de construire la courbe de la loi normale donnent, dans ce cas, un ajustement cohérent des données.
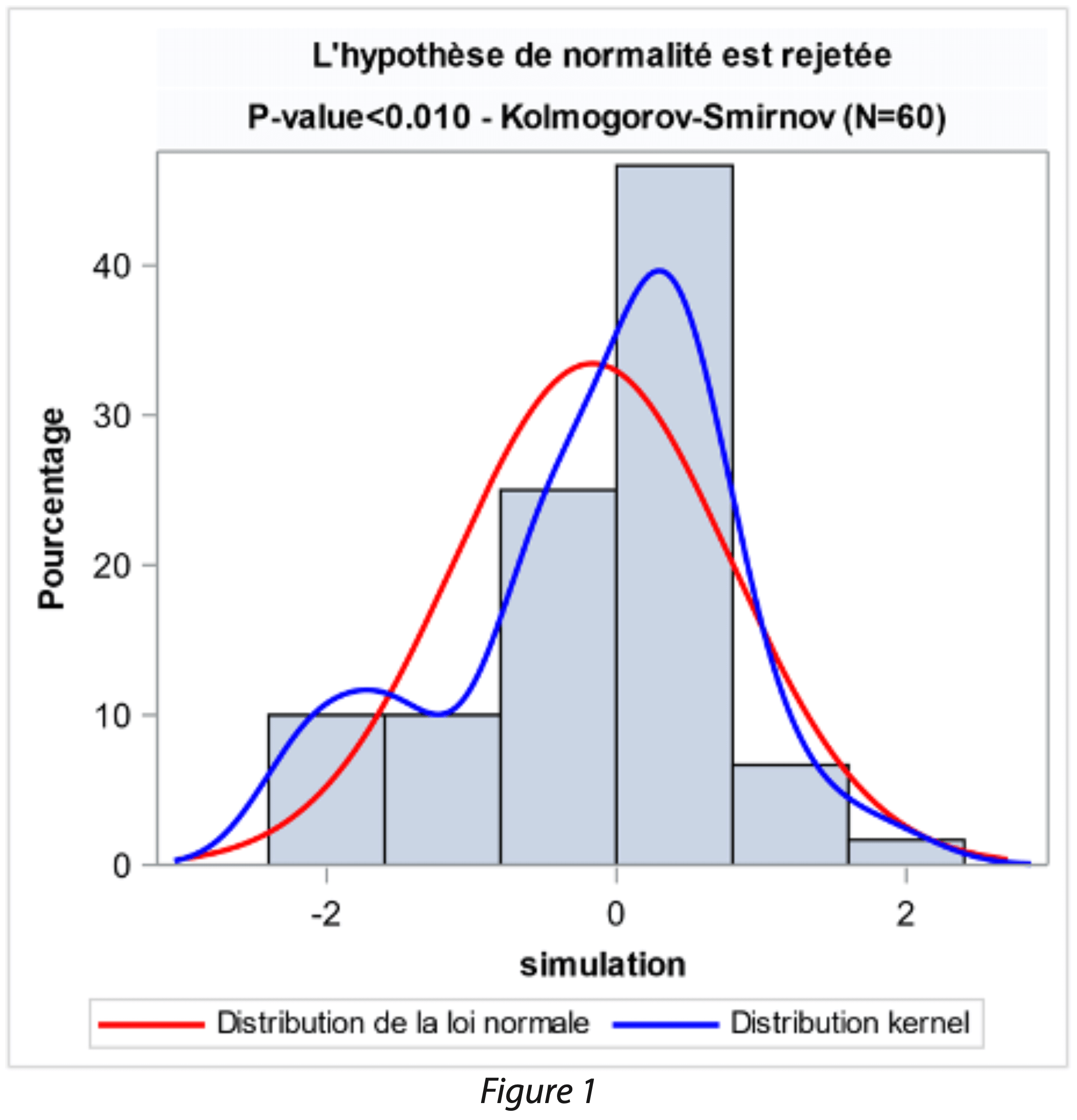
Il arrive fréquemment que la distribution s’éloigne fortement d’une distribution normale. Il est alors essentiel d’étudier son jeu de données afin de comprendre si cette non-normalité est explicable : Est-ce due à une erreur de saisie ? Les données sont-elles hétérogènes (dues à la présence de sous population) ? A-t-on des valeurs atypiques ? Avant tout calcul, il est important de challenger l’historique à étudier afin de s’assurer que les données sont fiables, complètes et représentatives du paramètre étudié.
Il arrive également que la distribution suive une loi connue, autre que la loi normale. Ce cas est étudié dans le chapitre suivant.
Approche 1 : Application d’une transformation
Une méthode classiquement appliquée est la transformation des données, par exemple l’application d’une transformation logarithmique.
Le principe est simple : le logarithme de chaque observation est calculé, puis la normalité est testée sur les valeurs transformées. Lorsque la normalité est vérifiée, les limites sont calculées sur les valeurs transformées et une transformation inverse des limites est effectuée pour revenir dans l’unité d’origine. Les limites sont alors dissymétriques mais le ratio est constant car :
- (limite supérieure)/moyenne = moyenne/(limite inférieure)
La transformation logarithmique est particulièrement efficace sur les données issues du vivant (réactions antigène-anticorps par exemple). En effet, il est connu que la distribution de nombreuses mesures biologiques est dissymétrique à droite et/ou a une variabilité qui augmente lorsque la moyenne augmente. Une transformation logarithmique permet souvent de retrouver une distribution normale et homoscédastique (Cf. Pharmacopée Européenne, chapitre 5.3 Statistical analysis of results of biological assays and tests).
Une autre approche consiste à rechercher parmi toutes les transformations disponibles dans les logiciels celle qui s’ajuste le mieux à un jeu de données. Dans des domaines très réglementés (domaine pharmaceutique par exemple), cette approche exploratoire est discutable car la distribution recommandée par le logiciel peut changer selon l’historique de données. Cette méthode peut également apporter un biais, donner des limites qui ne sont pas cohérentes avec les données ; ainsi, la transformation pourrait ne pas avoir de sens d’un point de vue scientifique.
Ainsi, l’application d’une transformation des données est une première approche pertinente lorsque la distribution sous-jacente est connue et qu’elle a un sens d’un point de vue scientifique. Les limites sont alors dissymétriques, tout en restant en accord avec la distribution sous-jacente.
Approche 2 : Intervalle de tolérance non-paramétrique
Lorsque la normalité n’est pas vérifiée, il est possible d’utiliser des intervalles de tolérances non-paramétriques. Cette méthode consiste toujours à encadrer un certain pourcentage de la population avec une certaine probabilité : lorsque la population n’est pas normale, elle consiste à retenir les quantiles empiriques du jeu de données, si le nombre d’échantillons est suffisant.
L’approche est décrite dans “STATISTICAL INTERVALS, A guide for Practitioners” de Gérald J. HAHN et William Q. MEEKER. Par exemple, si on souhaite calculer un intervalle de tolérance non-paramétrique bilatéral encadrant 90% des données avec une probabilité de 95%, il faut disposer de 46 données ; l’intervalle de tolérance par cette méthode non paramétrique est alors constitué de la plus petite et de la plus grande des 46 données.
Dans le cas où le nombre minimum de données n’est pas atteint, l’intervalle de tolérance est construit avec la plus petite et de la plus grande des données mais la probabilité doit être recalculée en appliquant la formule suivante : 1-α = 1-np (n-1) + (n-1)xpn où n est le nombre de données, et p la probabilité à encadrer. Ainsi, pour encadrer 90% de la population avec seulement 40 données, la probabilité recalculée est de 92%.
Lorsque le nombre de données est élevé, on retire les extrêmes puis on retient les données suivantes, en appliquant les tables statistiques fournies. Par exemple, si on dispose de 300 données, les limites sont constituées en utilisant la 11ième et la 290ième données lorsqu’elles sont classées par ordre croissant.
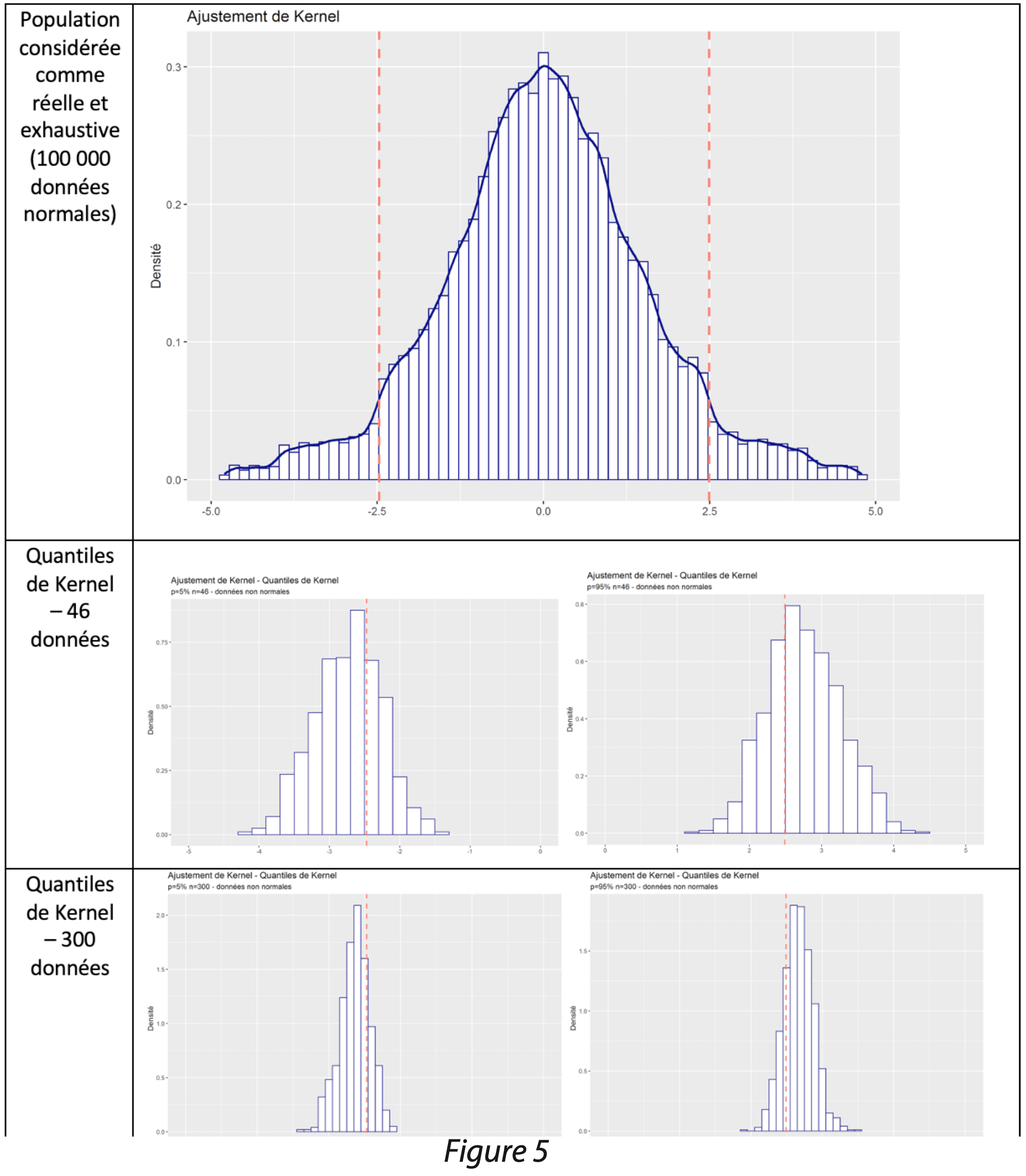
Afin de visualiser les résultats de cette méthode, des simulations ont été effectuées. Un jeu de 100 000 données a été simulé suivant une loi normale centrée réduite ; ce jeu de données est considéré comme une population réelle et exhaustive. Les quantiles d’intérêts 5% et 95% ont été calculés sur la population, appelés quantiles réels par la suite.
1 000 tirages aléatoires avec remise de 46 données ont été effectués dans la population réelle. Pour chaque tirage, le minimum et le maximum ont été retenus, conformément à la méthode des intervalles de tolérance non-paramétriques basés sur les quantiles empiriques.
1 000 tirages aléatoires avec remise de 300 données ont été effectués dans la population réelle. Pour chaque tirage, la 11ième et la 290ième données ont été sélectionnées, conformément à la méthode des intervalles de tolérance non-paramétriques basés sur les quantiles empiriques.
Les résultats des quantiles sur les tirages de 46 et 300 données sont ensuite comparés graphiquement aux quantiles réels (traits rouges).
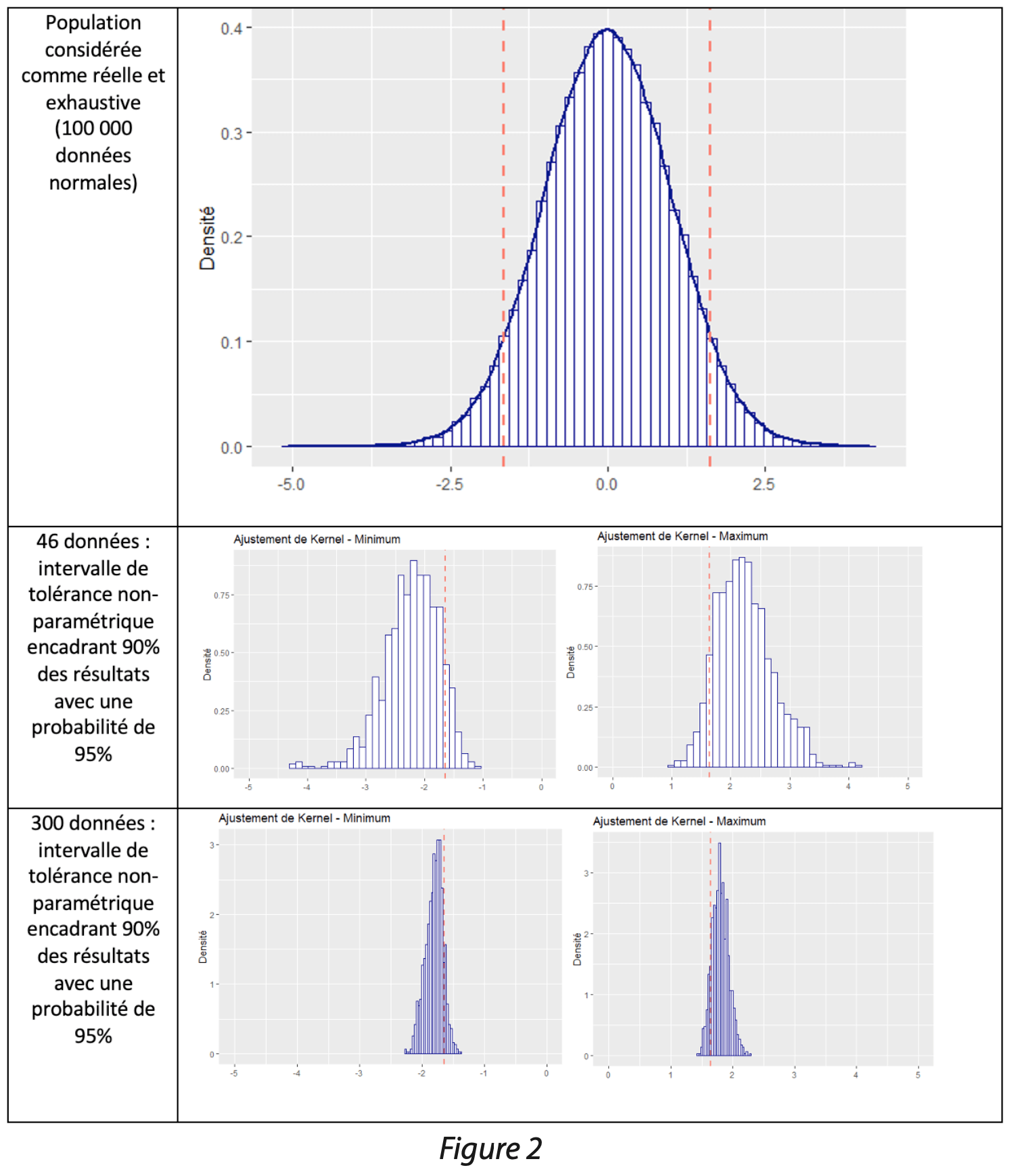
Les limites obtenues par la méthode de l’intervalle de tolérance non-paramétrique donnent des résultats supérieurs aux quantiles réels (traits rouges) dans une majorité des cas. Cette constatation est intrinsèque à la méthode qui a pour objectif d’encadrer un certain pourcentage de données, avec une certaine probabilité. Ces graphiques montrent que la probabilité d’être inférieure aux quantiles réels est en effet de 5% (5% des résultats sont inférieurs aux quantiles réels). On constate que la méthode est beaucoup plus précise lorsqu’on dispose de 300 données. Lorsque l’effectif est faible, les limites peuvent beaucoup varier : avec 46 données, les limites varient entre 1 et 4, pour une valeur attendue de 2 !
Des simulations ont également été effectuées sur des données non-normales. Il est à noter que de nombreuses causes peuvent générer une non-normalité ; seul le cas d’une loi avec des queues de distributions accentuées est présenté ici.
Comme précédemment, lorsque l’on dispose de 46 données, les estimations des limites peuvent être très éloignées du vrai quantile. En sélectionnant 300 données, les simulations sont peu dispersées ; en revanche, elles donnent un résultat médian assez éloigné du quantile réel. Ceci est expliqué par la présence de queues de distributions marquées. En fonction de la cause de la non-normalité, le résultat médian peut donc être plus ou moins proche du quantile réel.
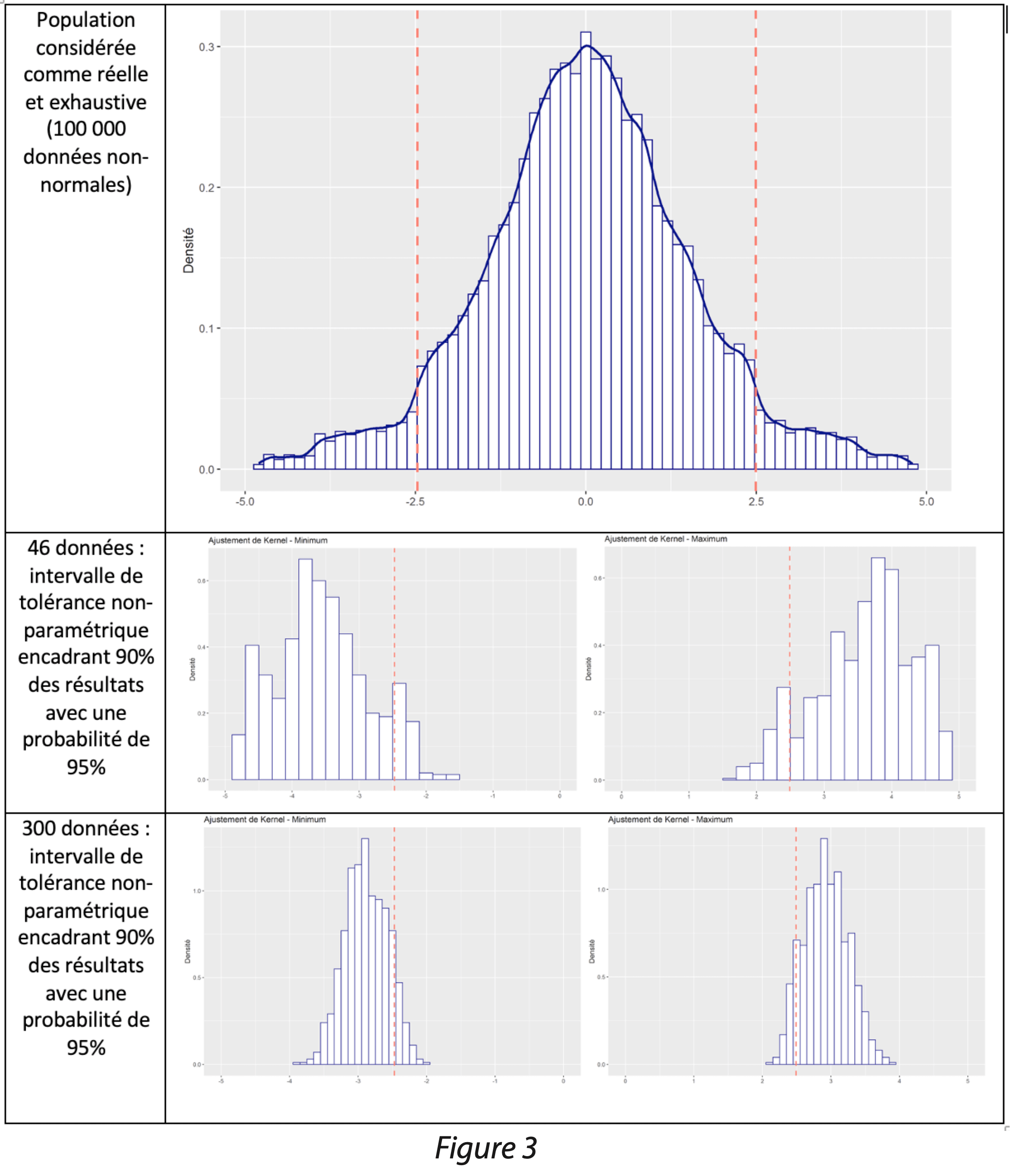
Conclusion
Pour conclure, cette méthode non-paramétrique consiste à retenir des quantiles, à condition que la taille de l’échantillon soit suffisamment grande. Cette méthode conservatrice garantit d’encadrer la population avec une certaine probabilité ; ainsi, dans (1-α)% des cas, elle va donner une estimation plus large que la valeur attendue, afin de garantir le risque fournisseur, au détriment du risque client.
Lorsque l’effectif est faible, la méthode est à utiliser avec précaution car elle peut donner des limites très éloignées des valeurs théoriques attendues. Plus l’effectif est grand, plus la méthode donne des limites proches des valeurs théoriques attendues.
Approche 3 : Utilisation des quantiles de l’estimateur non paramétrique de la densité – méthode Kernel
Une approche alternative consiste à utiliser les quantiles issus de l’estimateur non paramétrique de la densité pour calculer des intervalles, lorsque la normalité des données n’est pas vérifiée (méthode Kernel).
Le principe de cette méthode consiste à estimer la fonction de densité qui permet de calculer l’aire sous la courbe, puis à récupérer les quantiles correspondant à la proportion que l’on souhaite encadrer. Les simulations effectuées ici utilisent les paramètres par défaut du logiciel SAS : un noyau gaussien, et une estimation de la largeur de bande calculée par estimateur plug-in. Ce paramétrage par défaut est biaisé car il surestime les résultats pour un échantillon fini[1]. Des approches alternatives sont proposées à la fin de ce document.
Afin de visualiser les résultats de cette méthode, des simulations ont été effectuées. Un jeu de 100 000 données a été simulé suivant une loi normale centrée réduite ; ce jeu de données est considéré comme une population réelle et exhaustive. Les quantiles d’intérêts 5% et 95% ont été calculés sur la population appelés quantiles réels par la suite.
- 1 000 tirages aléatoires avec remise de 46 et 300 données ont été effectués dans la population réelle. Pour chaque tirage, calcul des quantiles :
- Calcul de l’estimateur non paramétrique de la densité des données et récupération des densités (Y) pour chaque x.
- Calcul des quantiles d’ordre 0.05 et 0.95 de l’estimation de la fonction de densité.
Les limites calculées à partir de l’ajustement de Kernel ont ensuite été comparées graphiquement aux quantiles réels (trait rouge dans figure 4).
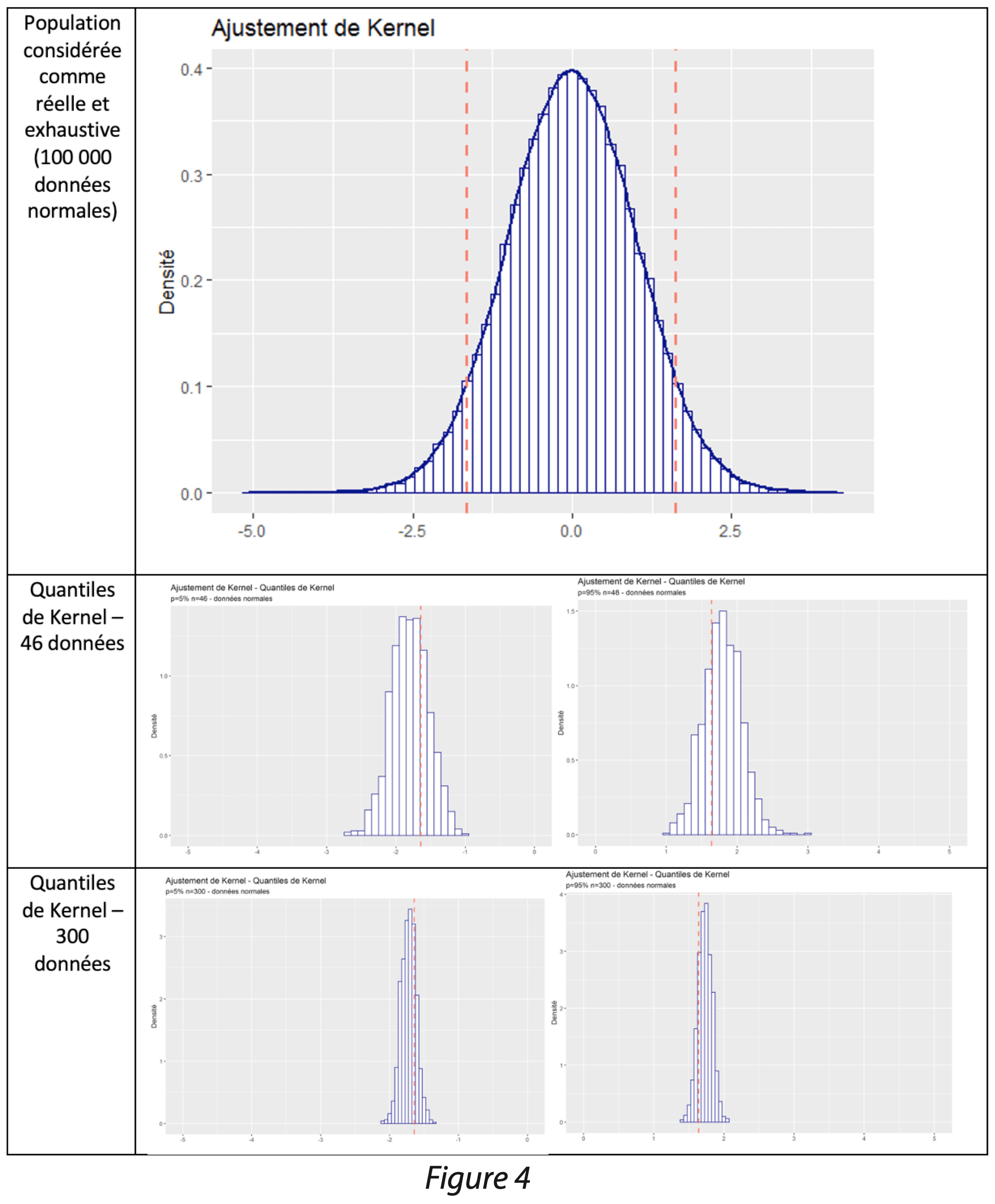
On constate que les quantiles issus de l’ajustement de Kernel sont peu étendus. Néanmoins, un léger biais est constaté car la distribution des quantiles est décalée par rapport à la valeur réelle, indiquée en rouge. Plus la taille de l’échantillon considéré est grande, plus la largeur de bande de l’estimateur non paramétrique de la densité est faible et plus le biais est faible.
Les simulations ont également été effectuées sur la population non- normale.
Le biais est également constaté sur les données non-normales.
2. Réduction du biais pour les quantiles de Kernel
Comme expliqué précédemment, la méthode des quantiles lissés issus de l’ajustement de Kernel, avec un noyau gaussien et une largeur de bande par estimateur plug-in (méthode par défaut de SAS), présente un biais sur les échantillons finis. Ce biais peut être amoindri à l’aide d’une procédure plus adaptée de calcul de l’estimateur non paramétrique de la densité (noyau d’Epanechnikov et calcul de l’estimateur à l’aide de validation croisée utilisant l’erreur quadratique moyenne intégrée, cf “An alternative method of cross-validation for the smoothing of density estimates ; ADRIAN W. BOWMAN“) mais aussi de rééchantillonnage bootstrap dans la procédure de validation croisée cf (“Confidence intervals for kernel density estimation ; Carlo V. Fiorio”). Ce paramétrage est possible avec le logiciel R.
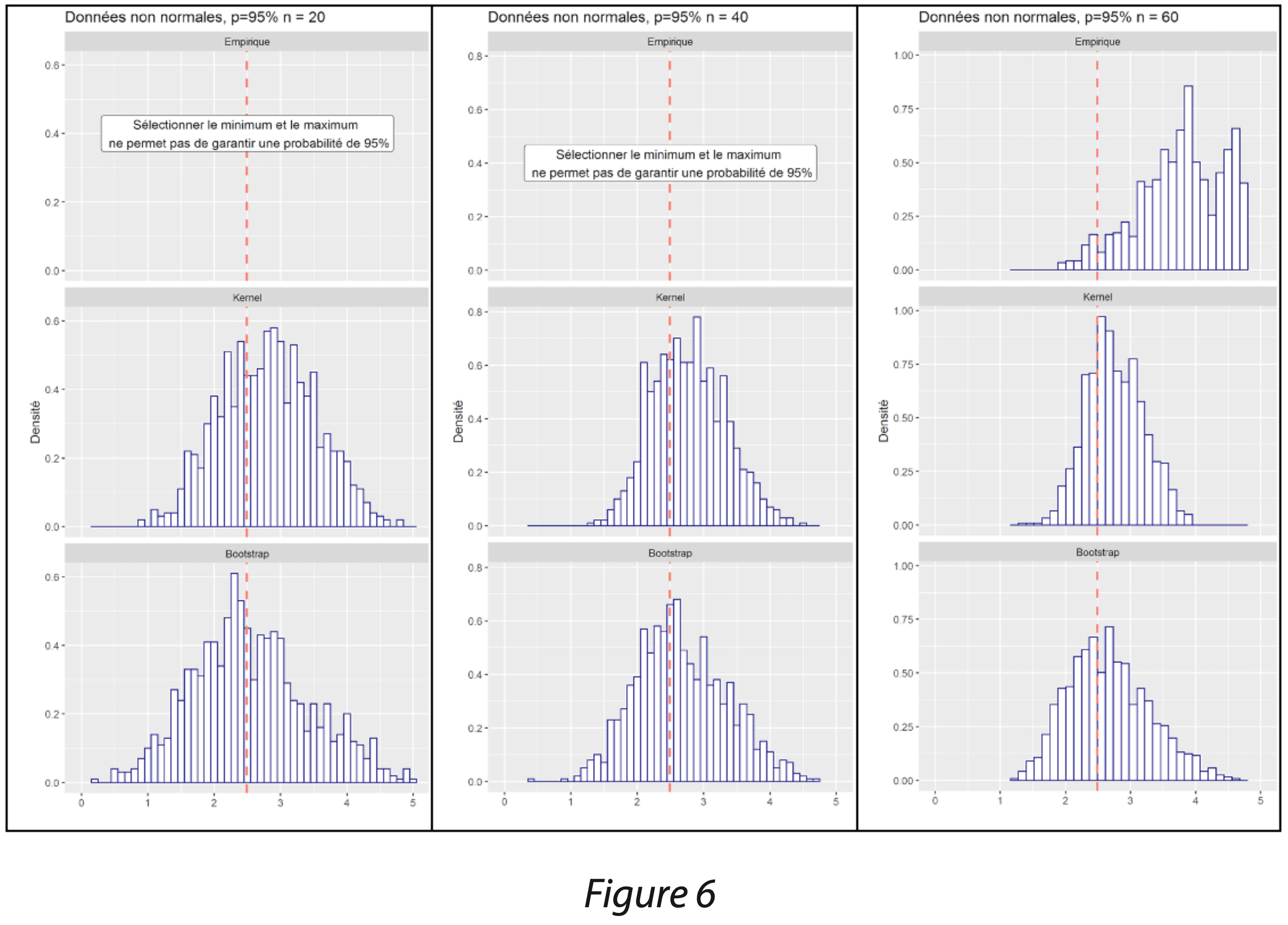
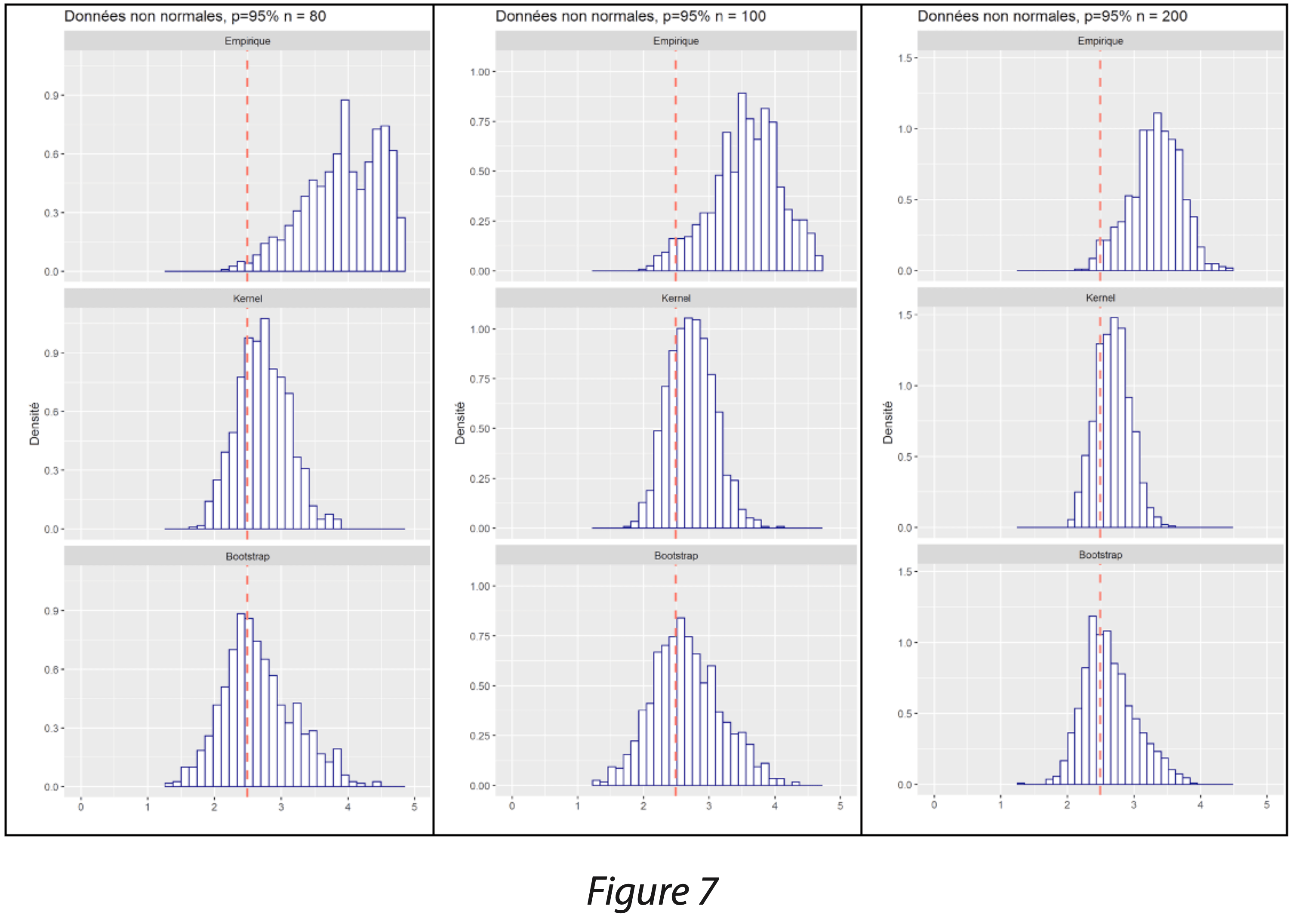
Ainsi, les performances des 3 méthodes ont été comparées :
- les quantiles empiriques selon la méthode non-paramétrique décrite dans le guide dans “STATISTICAL INTERVALS, A guide for Practitioners” de Gérald J. HAHN et William Q. MEEKER,
- les quantiles lissés issus de l’ajustement de Kernel, avec un noyau gaussien et une largeur de bande par estimateur plug-in (méthode par défaut de SAS, biaisée sur les échantillons finis),
- les quantiles lissés issus de l’ajustement de Kernel, avec une approche par rééchantillonnage bootstrap dans la validation croisée et un noyau d’Epanechnikov (méthode paramétrable sous R).
Dans le graphique des figures 6 et 7, seule la borne haute a été étudiée afin de calculer un intervalle de tolérance unilatéral, encadrant 95% de la population avec une probabilité de 95% également. D’après le guide, il est recommandé de disposer d’au moins 59 données pour garantir une probabilité de 95%.
La méthode des quantiles empirique décrite dans le guide de Gérald J. HAHN et William Q. MEEKER donne systématiquement des limites supérieures au quantile réel représenté par une ligne rouge : cette constatation est intrinsèque à la méthode qui consiste à garantir que la population sera bien encadrée dans 95% des cas. Elle est conservatrice et garantit le risque fournisseur, au détriment du risque client. Cette méthode n’est pas recommandée sur de petits échantillons car elle peut donner des résultats très supérieurs au quantile réel ; de plus, il faut s’assurer de disposer du nombre minimum de données.
La méthode des quantiles lissés issus de l’ajustement de Kernel avec un noyau gaussien et une largeur de bande par estimateur plug-in (méthode par défaut de SAS) donne les résultats les moins dispersés ; cependant, elle présente un léger biais en moyenne. La méthode est biaisée sur les échantillons finis, et ce biais diminue lorsque l’effectif est plus grand.
La méthode des quantiles lissés issus de l’ajustement de Kernel avec une approche par rééchantillonnage bootstrap dans la validation croisée et un noyau d’Epanechnikov (méthode paramétrable sous R) donne les résultats peu biaisés : ils sont globalement centrés sur la valeur théorique. En revanche, on observe une dispersion légèrement plus importante que les limites obtenues par la méthode par défaut de SAS.
2. Conclusion
Différentes méthodes statistiques proposent des intervalles pour suivre des données individuelles ; la plupart de ces méthodes exigent la normalité de la distribution sous-jacente des données.
Lorsque la normalité n’est pas vérifiée, les causes doivent être étudiées car il est parfois possible de conserver des méthodes paramétriques traditionnelles généralement plus puissantes, comme réaliser une transformation des données lorsque cela a du sens scientifiquement. Des méthodes non-paramétriques alternatives existent et peuvent également être utilisées.
Une méthode non-paramétrique par les quantiles empiriques est proposée dans le guide “STATISTICAL INTERVALS, A guide for Practitioners” de Gérald J. HAHN et William Q. MEEKER[2]. Cette méthode encadre une proportion de données avec une probabilité (1-α) choisie. Le risque de ne pas encadrer cette proportion est de α%. Ainsi, le risque fournisseur est maîtrisé, au détriment du risque client ; les limites sont plus larges que la proportion à encadrer.
Lorsque l’objectif de l’étude est d’être le plus proche possible de la proportion de données que l’on souhaite encadrer, alors la méthode des quantiles issus de l’ajustement de Kernel est préférable.
 |  |
Cette méthode donne des résultats moins dispersés, et plus proche de la valeur que l’on cherche à encadrer. Le noyau et la largeur de bande ont une influence sur l’ajustement ; l’utilisation d’un noyau gaussien et une largeur de bande par estimateur plug-in (méthode par défaut de SAS) donnent des résultats biaisés sur les échantillons finis. L’approche par rééchantillonnage bootstrap dans la validation croisée et un noyau d’Epanechnikov donne les résultats peu biaisés. Lorsque le risque client est important (un intervalle trop large n’est pas acceptable), la méthode des quantiles issus de l’ajustement de Kernel peut être retenue ; elle donne des limites moins larges, ce qui est généralement considéré comme un cas défavorable pour le fournisseur.
Références
[1] “Confidence intervals for kernel density estimation” par Carlo V. Fiorio ; The Stata Journal (2004)
[2] “STATISTICAL INTERVALS, A guide for Practitioners” de Gérald J. HAHN et William Q. MEEKER
Partager l’article



