
Sommaire
- Stratégie de contrôle et robotique : l'avenir des sites de production ?
- Un chargement de cartouches robotisé chez Lilly
- Small, flexible filling and packaging systems - using robots could mean great benefits
- Automated and instantaneous enumeration of viable microorganisms with Red One™, solid-phase cytometry platform
- Method analytical performance strategy in commercial quality control laboratories
- "Replicate Strategy" : mais quel est ce concept ?
- A3P International Congress 2020: Feedback and key messages from the Annex1 revision process panel discussion
- Conformité réglementaire : une réévaluation des relations stratégiques de sous-traitance dans la « nouvelle normalité »
"Replicate Strategy" : mais quel est ce concept ?
Comme Monsieur Jourdain faisait de la prose sans le savoir, beaucoup d’analystes appliquent une “replicate strategy”, sans le savoir non plus.
En effet, certains tests décrits dans les Pharmacopées sont basés sur une moyenne de plusieurs mesures et/ou de plusieurs déterminations sur plusieurs échantillons d’un même lot de produit fini (Uniformité de teneur, test de dissolution par exemple), voire même plusieurs séries d’analyses sur un même lot (titrage d’antibiotiques ou tests ELISA, par exemple).

D’autres “Replicate Strategies” peuvent aussi provenir de règles édictées dans des procédures internes : injection en double en HPLC = double mesure, par exemple.
Le chapitre <1220> paru dans Pharmacopeial Forum[1] propose de nombreuses démarches pour une meilleure appréhension du cycle de vie des méthodes analytiques, et en particulier la notion de “Replicate Strategy”. Ce texte est un prélude au futur guideline ICHQ14 qui focalisera sur l‘AQbD (Analytical Quality by Design), démarche volontaire pour mener un développement analytique raisonné, qui tient compte de l’usage prévu de la méthode, mais aussi des utilisateurs finaux de ces méthodes. Faciliter la vie de l’utilisateur final est en effet une quête indispensable pour tous les acteurs du développement analytique. Nous allons détailler en quoi une “Replicate Strategy” va dans le sens de cette quête. L’objectif de cet article est d’aborder de façon pragmatique les notions d’incertitude, qui peuvent rebuter voire effrayer nos analystes, afin d’en tirer les fruits dont chaque laboratoire rêve secrètement => réduire le risque de générer des résultats hors spécifications qui ne seront pas confirmés et ainsi, diminuer la documentation nécessaire pour investiguer et tracer les décisions qui seront prises.
D’autant plus que l’invalidation d’un résultat analytique est toujours une tâche délicate, qu’il convient de justifier clairement.
1. Contexte et définitions
Sources de variabilité
L’objectif de la “replicate strategy” est de diminuer l’impact des sources de variabilité d’une méthode analytique. Chaque méthode présente des sources de variabilité différentes, et l’étude approfondie de cette variabilité (pendant le développement et la validation de la méthode) est nécessaire pour adopter une stratégie de répétitions de tests efficace. Les 4 grandes sources de variabilité sont résumées dans le tableau1. Il est impossible de maîtriser l’ensemble des sources de variabilité. Mais il convient de comprendre et dompter les différentes sources issues d’étapes du process analytique lui-même. En fin de développement, la validation d’une méthode analytique permettra de mesurer la variabilité résiduelle qui impactera la fiabilité des mesures obtenues avec cette méthode.
Lors de la validation de méthode, l’étude de la Précision (Fidélité) permet d’étudier la dispersion des données (calcul de variances, d’écarts type et de Coefficients de Variation (CV), et d’évaluer :
- Un CV de répétabilité : proportionnel à l’épaisseur des niveaux 1+2 du tableau précédent ;
- Un CV de précision intermédiaire : proportionnel à l’épaisseur des niveaux 1+2+3.
Le niveau 1 est contrôlé régulièrement (qualification périodique d’équipement et Tests de conformité du système à chaque série d’analyse). Il peut toutefois varier d’un jour à l’autre, et cela se répercute sur le calcul du CV de précision intermédiaire.
Le niveau 2 est représentatif de la préparation d’échantillons. C’est la variabilité observée sur plusieurs déterminations à partir d’un même échantillon homogène. Cela consiste à répéter plusieurs fois le paragraphe “préparation d’échantillons” de la procédure analytique.
Plus cette préparation est complexe, plus ce niveau sera susceptible d’être une source de variabilité importante. La qualité de la description de préparation d’échantillons, comme les précisions apportées sur les modes de préparation, les durées d’agitation, l’aspect attendu des échantillons après chaque étape du traitement, sont autant d’éléments qui permettront d’éviter une variabilité différente d’un analyste à l’autre.
Le niveau 3 correspond à la variabilité observée entre les moyennes des différentes séries d’analyse sur un même lot homogène. Cela correspond à répéter plusieurs fois la procédure analytique dans son ensemble : préparation des réactifs, des diluants, des solutions de référence, etc… Plusieurs analystes et plusieurs équipements peuvent être impliqués durant les séries effectuées sur plusieurs jours durant la validation de la méthode.
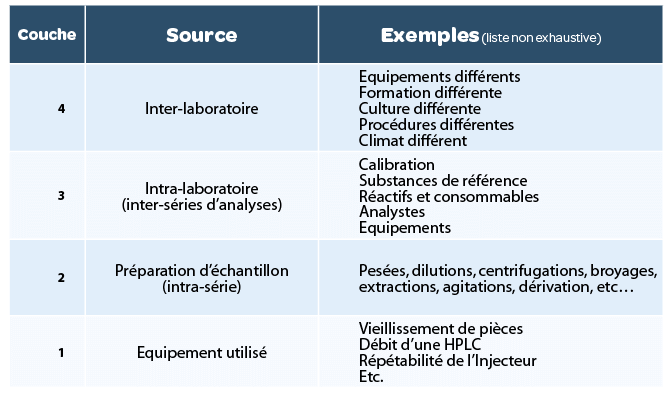
Ainsi, la variabilité entre les séries correspond à la variabilité inhérente aux pesées et préparations des solutions de calibration, à laquelle peut s’ajouter un effet équipement, un effet analyste, ou un effet de modification des conditions climatiques d’un jour à l’autre (température, humidité, ensoleillement). La préparation d’une solution de référence n’est généralement pas complexe, mais la plus grande attention doit y être attachée afin de limiter de telles variations inter-séries, qui sont fortement dommageables pour la qualité des résultats obtenus avec la méthode.
Le niveau 4 correspond à une potentielle variabilité entre plusieurs laboratoires, qui n’est généralement pas estimée en validation. Une telle variabilité existe, du fait d’habitudes de travail différentes d’un laboratoire à l’autre (procédures, formations, culture, etc…) et, parfois, d’environnement de travail différent (température, humidité, lumière, etc.). On analyse cette variabilité durant les étapes de transfert analytique qui jalonnent le cycle de vie des procédures analytiques.
Dans le cadre de la définition d’une “Replicate Strategy”, nous nous attarderons sur l’impact potentiel des épaisseurs des 2ème et 3ème niveau ou, de façon plus pratique et pragmatique, sur l’analyse des CV de répétabilité et de précision intermédiaire calculés durant la validation.
Intérêt d’une “Replicate Strategy”
En routine au laboratoire, chaque mesure individuelle sera soumise à l’ensemble des sources de variabilités et pourra varier avec un CV proche du CV de précision intermédiaire défini en validation.
Remarque : Il est bon de savoir qu’environ 95% des valeurs individuelles se situeront entre -2xCV et + 2xCV (avec l’hypothèse d’une distribution Normale des données, ce qui est le plus souvent le cas lors des dosages réalisés dans l’industrie pharmaceutique). Il est donc primordial de comprendre, maîtriser et diminuer la variabilité autant que possible durant le développement de la méthode analytique.
L’objectif d’une “Replicate Strategy” est de définir le nombre de séries de mesure et de mesures par série pour définir un résultat moyen, qui sera le résultat rapporté dans un rapport d’analyse et comparés aux spécifications du produit. Ne plus comparer chaque mesure individuelle permet de diminuer grandement la gestion de résultats OOS.
=> Répéter plusieurs analyses dans une même série permet de réduire l’impact du 2ème niveau, alors que faire plusieurs séries permet de réduire l’impact du 3ème niveau.
Quelques définitions et quelques calculs
Ecart type et Coefficient de Variation (CV)
Lors de la validation de méthode, on exploite les résultats de précision à travers une analyse de Variance (ANOVA). Cette analyse de variance permet de décomposer la variance totale observée lors de n séries de p répétitions en :
- une variance de répétabilité S²w (w pour within group) et Sw l’écart type de répétabilité,
- une variance inter-séries S²b (b pour between groups) et Sb l’écart type inter-séries,
- une variance de précision intermédiaire S²IP = S²w+ S²b et SIP l’écart type de précision intermédiaire.
Pour chacun des écart-types calculés, on peut définir le CV, qui est la variance rapportée à la moyenne, exprimé en pourcentage de la moyenne. Afin de simplifier les propos pour illustrer l’intérêt d’une “Replicate Strategy”, nous prendrons la moyenne = 100, ce qui permet d’avoir CV = écart type/moyenne x 100 = écart type.
Le CV de répétabilité est donc alors égal à l’écart type de répétabilité Sw, et est proportionnel aux épaisseurs des niveaux 1+2, alors que le CV de précision intermédiaire est alors égal à l’écart type de précision intermédiaire SIP et est proportionnel aux niveaux 1+2+3.
Ecart type d’une moyenne
L’écart type d’une moyenne de n résultats est réduit d’un facteur √n par rapport à l’écart type initial (ou la variance est réduite d’un facteur n). Dans le cas qui nous intéresse, si lors du dosage on effectue p séries, avec n répétitions par série, la variance de répétabilité sera réduite d’un facteur n x p et la variance de précision intermédiaire sera réduite d’un facteur p. Les répétitions ont donc pour effet de “réduire” l’épaisseur des niveaux évalués durant la validation.
=> Moyenner plusieurs mesures réduit donc l’incertitude associée au résultat moyen ainsi calculé.
Incertitude de mesure
Ici encore, l’objectif est de comprendre le concept d’incertitude, et non pas d’en donner toutes les définitions existant dans la littérature. Je remercie donc les lecteurs de ne pas me blâmer pour la potentielle incertitude de mes propos sur l’incertitude…
L’incertitude d’une mesure est directement liée à la variabilité de la méthode servant à la générer. Chaque mesure n’est en effet qu’une estimation de la valeur “vraie”, plus ou moins proche de cette valeur vraie.
D’un point de vue mathématique, elle est sous une forme U=k.√variance, avec k un facteur de couverture, constante statistique associée à une probabilité (pour une distribution Normale et une probabilité de 95%, k=2 est fréquemment utilisé : cela rejoint la remarque édictée précédemment).
Avec les résultats de la validation, la variance est décomposée en variance intra-run et inter-run. Ainsi, l’incertitude associée est U=k.√(S2 w + S²b).
Pour un résultat provenant de la moyenne de p séries, avec n répétitions par série, on peut définir l’incertitude de ce résultat moyen (U’) avec la formule suivante, décrite par Schofield et al.[2]
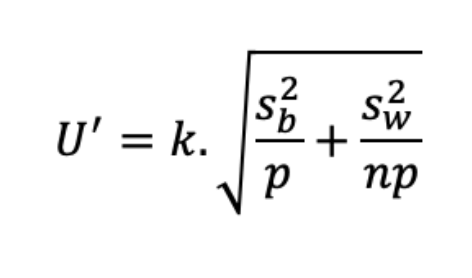
Ainsi, l’incertitude diminue quand on augmente n et/ou p.
La connaissance de l’importance relative des 2ème et 3ème niveaux des sources de variabilité permet justement de définir, s’il vaut mieux augmenter n, p, voire les 2 pour obtenir un résultat moyen qui ait une incertitude inférieure au niveau qu’on peut tolérer.
2. Analyse de différents scénarii
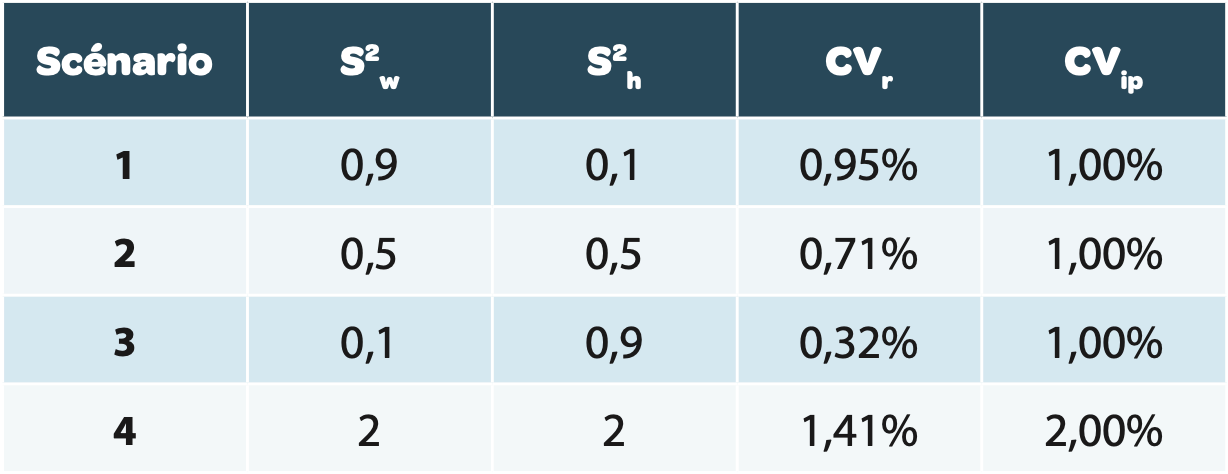
L’utilisation de la formule d’incertitude du résultat moyen U’ est simulée dans différents scénarii résumés dans le tableau 2. Rappel : pour le calcul du CV des différents scénarii, la valeur moyenne est prise à 100%.
Explication des différents scenarii
Pour les scénarii 1 à 3
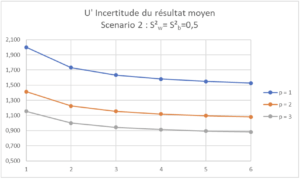
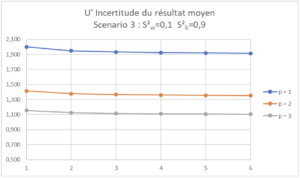
Le CVIP est identique (correspondant à l’épaisseur des niveaux 1, 2 et 3), mais la variabilité est répartie différemment entre l’intra-série (niveau 1+2) et l’inter-série (niveau 3):
Pour le scénario 1
L’épaisseur du 3ème niveau est faible par rapport au 2ème.
Pour le scénario 2
La variabilité est également répartie entre intra et inter séries. Cela correspond à l’exemple fourni dans le stimuli de l’USP[2].
Pour le scénario 3
L’épaisseur du 3ème niveau est importante par rapport au 2ème . Pour le scénario 4
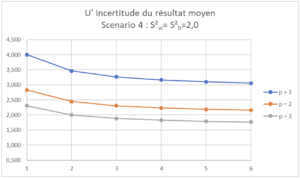
Le CVIP est porté à 2% avec une variabilité répartie entre intra et inter-série, afin d’illustrer l’impact important d’une augmentation de la variabilité générale sur l’incertitude globale.
Analyse des différents scenarii
Pour ces différents scénarii, l’impact des variations de p (1, 2 ou 3 séries distinctes) et de n (1 à 6 répétitions par série) est représenté graphiquement avec une courbe par valeur de p et le nombre de répétitions par série, n, sur l’axe des X:
A la lecture de ces courbes, il est facile de définir la procédure analytique en termes de nombre de séries et de répétitions par séries pour définir un résultat moyen ayant une incertitude réduite en deçà d’une limite qu’on aura fixée en amont.
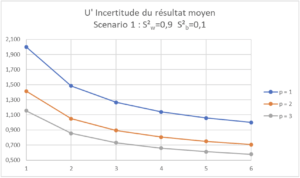 | Scenario 1 (CVr=0,95%, CVip=1,0%) Dans ce Scenario 1, on voit qu’augmenter n ou p a un effet sur l’incertitude du résultat moyen. |
 | Scenario 2 (CVr=0,71%, CVip=1,0%) Dans ce Scenario 2, on voit qu’augmenter p a plus d’effet sur l’incertitude du résultat moyen que d’augmenter n. |
 | Scenario 3 (CVr=0,32%, CVip=1,0%) Dans ce Scenario 3, on voit qu’augmenter n n’a quasiment aucun effet sur l’incertitude du résultat moyen, car la variabilité est essentiellement inter-série. |
 | Scenario 4 (CVr=1,41%, CVip=2,0%) Dans ce Scenario 4, la variabilité de l’analyse est telle qu’aucune “Replicate Strategy” raisonnable en termes d’activité de laboratoire de Contrôle Qualité ne permettrait d’assurer une incertitude du résultat moyen inférieure ou égale à 1,5%. |
Si l’incertitude maximale du résultat moyen est fixée à 2,0%, il faudra prévoir 3 séries avec au moins 2 répétitions par série (p=3, n=2)
Il convient à chacun de définir clairement l’incertitude maximale qu’il pourra tolérer pour le résultat qu’il souhaite obtenir pour définir la “Replicate Strategy” adaptée à sa méthode. Cette incertitude dépendra des spécifications du produit, en lien avec l’index thérapeutique du composé testé. Dans un article[3], Barnett et al. proposent de fixer l’incertitude maximale à 60% de la “marge de manœuvre” des spécifications.
Pour une spécification fixée entre 95.0 et 105.0%, la marge de manœuvre autour de la valeur cible est de ±5.0%. L’incertitude maximale du résultat moyen pourrait alors être fixée à 3.0% dans ce cas de figure. Ce type de calcul et les illustrations associées sont des outils précieux pour définir dans la procédure analytique le résultat qui sera rapporté pour être comparé aux spécifications.
3. Conclusion
La “Replicate Strategy” décrite dans le chapitre <1220> draft édité dans Pharmacopeial Forum[1] est un outil permettant de fiabiliser les résultats générés au laboratoire et diminuer le risque d’occurrence de résultats hors spécifications qui seraient dus à la variabilité intrinsèque de la méthode. Une telle stratégie est définie méthode par méthode.
La stratégie définie doit être clairement décrite dans la méthode qui a été approuvée. Elle fait donc partie intégrante de la procédure analytique permettant de contrôler le produit au laboratoire.
Comme décrit dans le guide FDA sur les OOS [4], la “Replicate Strategy”, qui permet de ne comparer que le résultat moyen aux spécifications du produit, nécessite d’associer un critère sur la variabilité des résultats individuels en plus du critère sur la valeur moyenne obtenue. Seul le respect conjoint des 2 critères permet de conclure à la conformité de l’échantillon testé.
Le second critère sur la variabilité peut être basé sur un écart maximal acceptable (EMA) entre les valeurs individuelles, sur le CV calculé sur les valeurs individuelles, ou encore sur le calcul d’un intervalle de confiance. Les différentes façons de fixer un tel critère feront certainement partie des futurs débats sur la gestion pragmatique et pratique des procédures analytiques tout au long du cycle de vie du produit. En tout cas, cela fera partie des débats du GIC A3P sur le cycle de vie des méthodes analytiques, constitué en octobre 2020, qui vous tiendra au courant des résultats de ses réflexions.
Partager l’article


Gérald de FONTENAY – CEBIPHAR
Depuis plus de 25 ans, Gérald a assuré différents postes au sein de sociétés de services analytiques et de CDMO. Aujourd’hui Directeur Scientifique et Technique chez Cebiphar, il continue à oeuvrer pour garantir le maximum de fiabilité aux résultats qui sont générés dans ses laboratoires. Il apporte son expertise en validation, vérification et transfert de méthodes analytiques auprès des chefs de projets et des clients de Cebiphar, pour assurer le succès des projets qui lui sont confiés.
gdefontenay@cebiphar.com
Glossaire
QbD : Analytical Quality by Design
CV : Coefficient de Variation (Relative Standard Deviation RSD en Anglais)
CVr : CV de répétabilité
CVip : CV de précision intermédiaire
ICH : International Council for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use
OOS : “Out of Specifications” Résultat hors critère d’acceptation.
USP : United States Pharmacopeia
Références
[1] USP <1220> Analytical Procedure Life Cycle. Pharmacopeial Forum 46(5) (2020)
[2] T. Schofield, E. van den Heuvel, J. Weitzel, D. Lansky, P. Borman. Distinguishing the analytical method from the analytical procedure to support the USP Analytical Procedure Life Cycle Paradigm. Stimuli to the revision process. Pharmacopeial Forum 46(2) (2020)
[3] K.L. Barnett, P.L. McGregor, G.P. Martin, D.J. LeBlond, M.L.J Weitzel, J. Ermer, S. Walfish, P. Nethercote, G.S. Gratzl, E. Kovacs. Analytical Target Profile: Structure and Application throughout the Analytical Lifecycle. Pharmacopeial Forum 42(5) (2016)
[4] Investigating Out-of-Specification (OOS). Test Results for Pharmaceutical Production. Guidance for Industry. FDA (2006)
